 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoVM: Achieving Precise Ego-Localization using Lightweight Vectorized Maps
Jul 18, 2023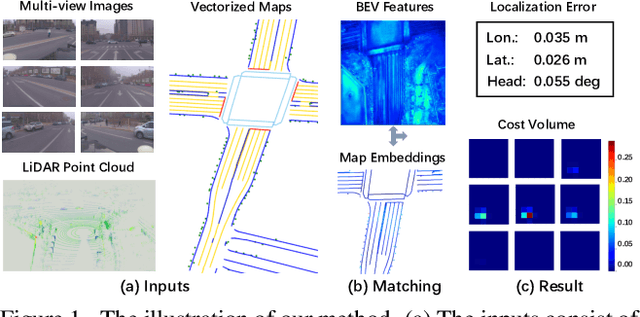

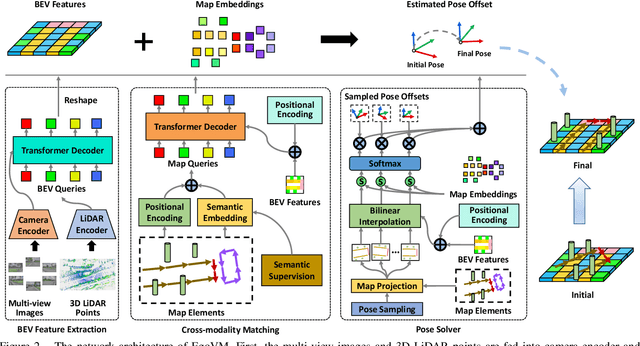

Accurate and reliable ego-localization is critical for autonomous driving. In this paper, we present EgoVM, an end-to-end localization network that achieves comparable localization accuracy to prior state-of-the-art methods, but uses lightweight vectorized maps instead of heavy point-based maps. To begin with, we extract BEV features from online multi-view images and LiDAR point cloud. Then, we employ a set of learnable semantic embeddings to encode the semantic types of map elements and supervise them with semantic segmentation, to make their feature representation consistent with BEV features. After that, we feed map queries, composed of learnable semantic embeddings and coordinates of map elements, into a transformer decoder to perform cross-modality matching with BEV features. Finally, we adopt a robust histogram-based pose solver to estimate the optimal pose by searching exhaustively over candidate poses. We comprehensively validate the effectiveness of our method using both the nuScenes dataset and a newly collected dataset. The experimental results show that our method achieves centimeter-level localization accuracy, and outperforms existing methods using vectorized maps by a large margin. Furthermore, our model has been extensively tested in a large fleet of autonomous vehicles under various challenging urban scenes.