 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified BEV Model for Joint Learning of 3D Local Features and Overlap Estimation
Mar 14, 2023
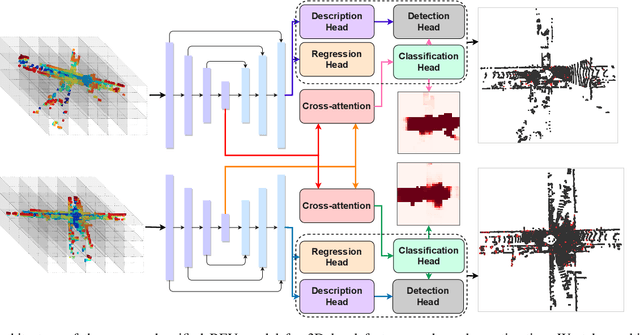


Pairwise point cloud registration is a critical task for many applications, which heavily depends on finding correct correspondences from the two point clouds. However, the low overlap between input point clouds causes the registration to fail easily, leading to mistaken overlapping and mismatched correspondences, especially in scenes where non-overlapping regions contain similar structures. In this paper, we present a unified bird's-eye view (BEV) model for jointly learning of 3D local features and overlap estimation to fulfill pairwise registration and loop closure. Feature description is performed by a sparse UNet-like network based on BEV representation, and 3D keypoints are extracted by a detection head for 2D locations, and a regression head for heights. For overlap detection, a cross-attention module is applied for interacting contextual information of input point clouds, followed by a classification head to estimate the overlapping region. We evaluate our unified model extensively on the KITTI dataset and Apollo-SouthBay dataset. The experiments demonstrate that our method significantly outperforms existing methods on overlap estimation, especially in scenes with small overlaps. It also achieves top registration performance on both datasets in terms of translation and rotation errors.
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Sep 07, 2022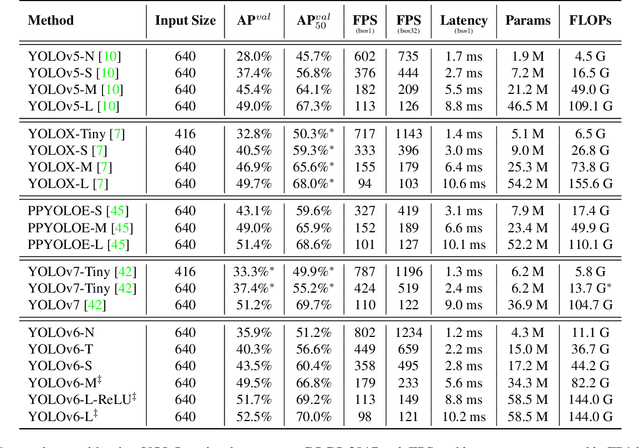
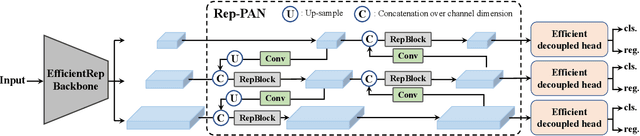
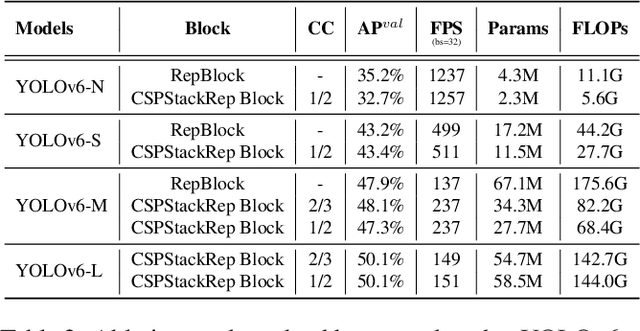
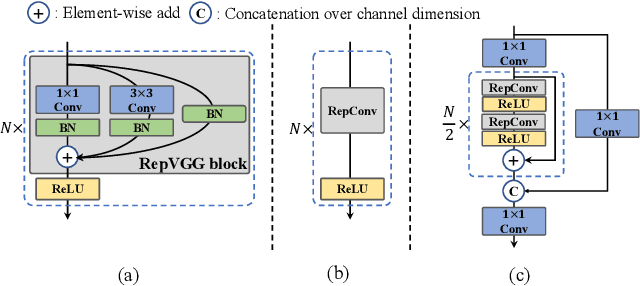
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at https://github.com/meituan/YOLOv6.
Omni-frequency Channel-selection Representations for Unsupervised Anomaly Detection
Mar 01, 2022



Density-based and classification-based methods have ruled unsupervised anomaly detection in recent years, while reconstruction-based methods are rarely mentioned for the poor reconstruction ability and low performance. However, the latter requires no costly extra training samples for the unsupervised training that is more practical, so this paper focuses on improving this kind of method and proposes a novel Omni-frequency Channel-selection Reconstruction (OCR-GAN) network to handle anomaly detection task in a perspective of frequency. Concretely, we propose a Frequency Decoupling (FD) module to decouple the input image into different frequency components and model the reconstruction process as a combination of parallel omni-frequency image restorations, as we observe a significant difference in the frequency distribution of normal and abnormal images. Given the correlation among multiple frequencies, we further propose a Channel Selection (CS) module that performs frequency interaction among different encoders by adaptively selecting different channels. Abundant experiments demonstrate the effectiveness and superiority of our approach over different kinds of methods, e.g., achieving a new state-of-the-art 98.3 detection AUC on the MVTec AD dataset without extra training data that markedly surpasses the reconstruction-based baseline by +38.1 and the current SOTA method by +0.3. Source code will be available at https://github.com/zhangzjn/OCR-GAN.