 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadPainter: Points Are Ideal Navigators for Topology transformER
Jul 22, 2024



Topology reasoning aims to provide a precise understanding of road scenes, enabling autonomous systems to identify safe and efficient routes. In this paper, we present RoadPainter, an innovative approach for detecting and reasoning the topology of lane centerlines using multi-view images. The core concept behind RoadPainter is to extract a set of points from each centerline mask to improve the accuracy of centerline prediction. We start by implementing a transformer decoder that integrates a hybrid attention mechanism and a real-virtual separation strategy to predict coarse lane centerlines and establish topological associations. Then, we generate centerline instance masks guided by the centerline points from the transformer decoder. Moreover, we derive an additional set of points from each mask and combine them with previously detected centerline points for further refinement. Additionally, we introduce an optional module that incorporates a Standard Definition (SD) map to further optimize centerline detection and enhance topological reasoning performance. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of RoadPainter.
A Unified BEV Model for Joint Learning of 3D Local Features and Overlap Estimation
Mar 14, 2023
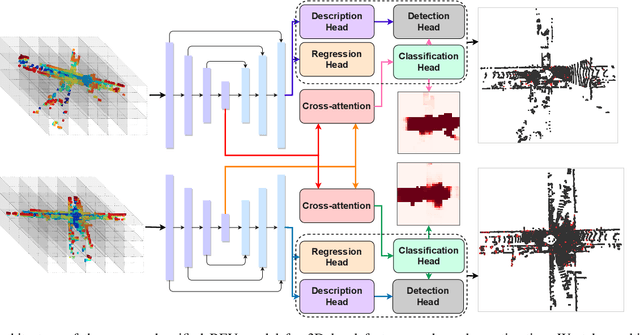


Pairwise point cloud registration is a critical task for many applications, which heavily depends on finding correct correspondences from the two point clouds. However, the low overlap between input point clouds causes the registration to fail easily, leading to mistaken overlapping and mismatched correspondences, especially in scenes where non-overlapping regions contain similar structures. In this paper, we present a unified bird's-eye view (BEV) model for jointly learning of 3D local features and overlap estimation to fulfill pairwise registration and loop closure. Feature description is performed by a sparse UNet-like network based on BEV representation, and 3D keypoints are extracted by a detection head for 2D locations, and a regression head for heights. For overlap detection, a cross-attention module is applied for interacting contextual information of input point clouds, followed by a classification head to estimate the overlapping region. We evaluate our unified model extensively on the KITTI dataset and Apollo-SouthBay dataset. The experiments demonstrate that our method significantly outperforms existing methods on overlap estimation, especially in scenes with small overlaps. It also achieves top registration performance on both datasets in terms of translation and rotation errors.