 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOSD-Net: Joint Semantic Object Segmentation and Depth Estimation from Monocular images
Paper and Code
Jan 19, 2021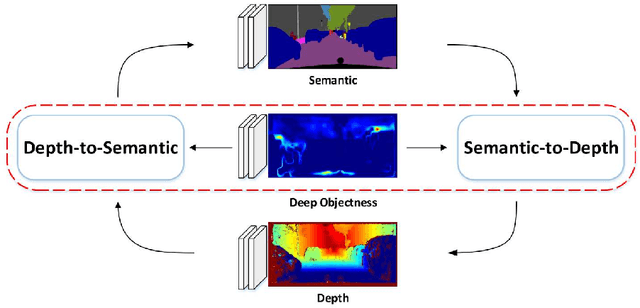
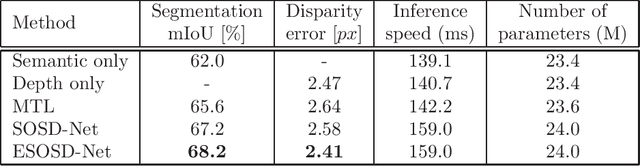
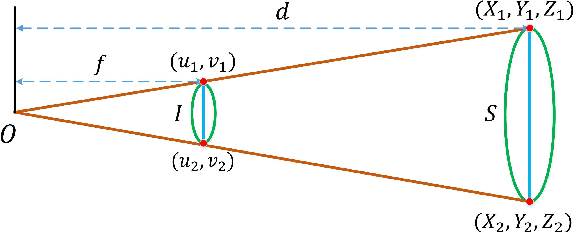
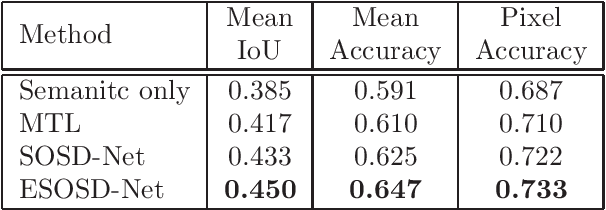
Depth estimation and semantic segmentation play essential roles in scene understanding. The state-of-the-art methods employ multi-task learning to simultaneously learn models for these two tasks at the pixel-wise level. They usually focus on sharing the common features or stitching feature maps from the corresponding branches. However, these methods lack in-depth consideration on the correlation of the geometric cues and the scene parsing. In this paper, we first introduce the concept of semantic objectness to exploit the geometric relationship of these two tasks through an analysis of the imaging process, then propose a Semantic Object Segmentation and Depth Estimation Network (SOSD-Net) based on the objectness assumption. To the best of our knowledge, SOSD-Net is the first network that exploits the geometry constraint for simultaneous monocular depth estimation and semantic segmentation. In addition, considering the mutual implicit relationship between these two tasks, we exploit the iterative idea from the expectation-maximization algorithm to train the proposed network more effectively. Extensive experimental results on the Cityscapes and NYU v2 dataset are presented to demonstrate the superior performance of the proposed approach.