 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Panel Layouts Define Manga: Insights from Visual Ablation Experiments
Dec 26, 2024



Today, manga has gained worldwide popularity. However, the question of how various elements of manga, such as characters, text, and panel layouts, reflect the uniqueness of a particular work, or even define it, remains an unexplored area. In this paper, we aim to quantitatively and qualitatively analyze the visual characteristics of manga works, with a particular focus on panel layout features. As a research method, we used facing page images of manga as input to train a deep learning model for predicting manga titles, examining classification accuracy to quantitatively analyze these features. Specifically, we conducted ablation studies by limiting page image information to panel frames to analyze the characteristics of panel layouts. Through a series of quantitative experiments using all 104 works, 12 genres, and 10,122 facing page images from the Manga109 dataset, as well as qualitative analysis using Grad-CAM, our study demonstrates that the uniqueness of manga works is strongly reflected in their panel layouts.
Code Generation for Unknown Libraries via Reading API Documentations
Feb 16, 2022


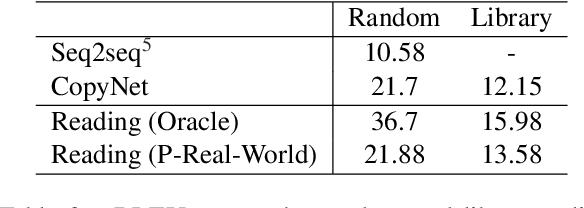
Open-domain code generation is a challenging problem because the set of functions and classes that we use are frequently changed and extended in programming communities. We consider the challenge of code generation for unknown libraries without additional training. In this paper, we explore a framework of code generation that can refer to relevant API documentations like human programmers to handle unknown libraries. As a first step of this direction, we implement a model that can extract relevant code signatures from API documentations based on a natural language intent and copy primitives from the extracted signatures. Moreover, to evaluate code generation for unknown libraries and our framework, we extend an existing dataset of open-domain code generation and resplit it so that the evaluation data consist of only examples using the libraries that do not appear in the training data. Experiments on our new split show that baseline encoder-decoder models cannot generate code using primitives of unknown libraries as expected. In contrast, our model outperforms the baseline on the new split and can properly generate unknown primitives when extracted code signatures are noiseless.
Filling Missing Paths: Modeling Co-occurrences of Word Pairs and Dependency Paths for Recognizing Lexical Semantic Relations
Sep 10, 2018



Recognizing lexical semantic relations between word pairs is an important task for many applications of natural language processing. One of the mainstream approaches to this task is to exploit the lexico-syntactic paths connecting two target words, which reflect the semantic relations of word pairs. However, this method requires that the considered words co-occur in a sentence. This requirement is hardly satisfied because of Zipf's law, which states that most content words occur very rarely. In this paper, we propose novel methods with a neural model of $P(path|w_1, w_2)$ to solve this problem. Our proposed model of $P(path|w_1, w_2)$ can be learned in an unsupervised manner and can generalize the co-occurrences of word pairs and dependency paths. This model can be used to augment the path data of word pairs that do not co-occur in the corpus, and extract features capturing relational information from word pairs. Our experimental results demonstrate that our methods improve on previous neural approaches based on dependency paths and successfully solve the focused problem.
Neural Latent Relational Analysis to Capture Lexical Semantic Relations in a Vector Space
Sep 10, 2018



Capturing the semantic relations of words in a vector space contributes to many natural language processing tasks. One promising approach exploits lexico-syntactic patterns as features of word pairs. In this paper, we propose a novel model of this pattern-based approach, neural latent relational analysis (NLRA). NLRA can generalize co-occurrences of word pairs and lexico-syntactic patterns, and obtain embeddings of the word pairs that do not co-occur. This overcomes the critical data sparseness problem encountered in previous pattern-based models. Our experimental results on measuring relational similarity demonstrate that NLRA outperforms the previous pattern-based models. In addition, when combined with a vector offset model, NLRA achieves a performance comparable to that of the state-of-the-art model that exploits additional semantic relational data.