 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Confusions in the ASR Channel for Improved Topic-based Language Model Adaptation
Paper and Code
Mar 21, 2013
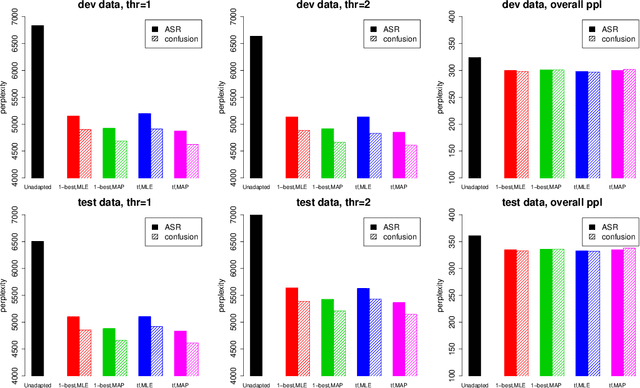
Human language is a combination of elemental languages/domains/styles that change across and sometimes within discourses. Language models, which play a crucial role in speech recognizers and machine translation systems, are particularly sensitive to such changes, unless some form of adaptation takes place. One approach to speech language model adaptation is self-training, in which a language model's parameters are tuned based on automatically transcribed audio. However, transcription errors can misguide self-training, particularly in challenging settings such as conversational speech. In this work, we propose a model that considers the confusions (errors) of the ASR channel. By modeling the likely confusions in the ASR output instead of using just the 1-best, we improve self-training efficacy by obtaining a more reliable reference transcription estimate. We demonstrate improved topic-based language modeling adaptation results over both 1-best and lattice self-training using our ASR channel confusion estimates on telephone conversations.