 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Quantifying How Pre-Training and Context Benefit In-Context Learning
Oct 26, 2025


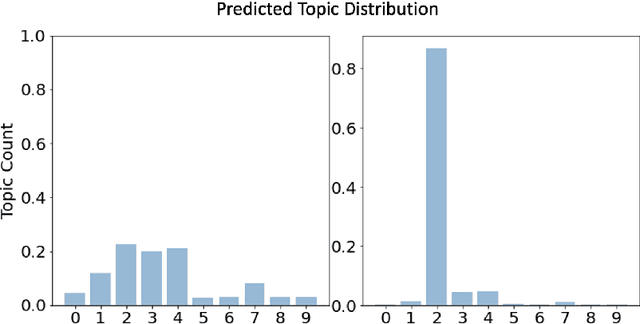
Pre-trained large language models have demonstrated a strong ability to learn from context, known as in-context learning (ICL). Despite a surge of recent applications that leverage such capabilities, it is by no means clear, at least theoretically, how the ICL capabilities arise, and in particular, what is the precise role played by key factors such as pre-training procedure as well as context construction. In this work, we propose a new framework to analyze the ICL performance, for a class of realistic settings, which includes network architectures, data encoding, data generation, and prompt construction process. As a first step, we construct a simple example with a one-layer transformer, and show an interesting result, namely when the pre-train data distribution is different from the query task distribution, a properly constructed context can shift the output distribution towards the query task distribution, in a quantifiable manner, leading to accurate prediction on the query topic. We then extend the findings in the previous step to a more general case, and derive the precise relationship between ICL performance, context length and the KL divergence between pre-train and query task distribution. Finally, we provide experiments to validate our theoretical results.
Effectively Steer LLM To Follow Preference via Building Confident Directions
Mar 04, 2025Having an LLM that aligns with human preferences is essential for accommodating individual needs, such as maintaining writing style or generating specific topics of interest. The majority of current alignment methods rely on fine-tuning or prompting, which can be either costly or difficult to control. Model steering algorithms, which modify the model output by constructing specific steering directions, are typically easy to implement and optimization-free. However, their capabilities are typically limited to steering the model into one of the two directions (i.e., bidirectional steering), and there has been no theoretical understanding to guarantee their performance. In this work, we propose a theoretical framework to understand and quantify the model steering methods. Inspired by the framework, we propose a confident direction steering method (CONFST) that steers LLMs via modifying their activations at inference time. More specifically, CONFST builds a confident direction that is closely aligned with users' preferences, and this direction is then added to the activations of the LLMs to effectively steer the model output. Our approach offers three key advantages over popular bidirectional model steering methods: 1) It is more powerful, since multiple (i.e. more than two) users' preferences can be aligned simultaneously; 2) It is simple to implement, since there is no need to determine which layer to add the steering vector to; 3) No explicit user instruction is required. We validate our method on GPT-2 XL (1.5B), Mistral (7B) and Gemma-it (9B) models for tasks that require shifting the output of LLMs across various topics and styles, achieving superior performance over competing methods.
Unraveling the Gradient Descent Dynamics of Transformers
Nov 12, 2024



While the Transformer architecture has achieved remarkable success across various domains, a thorough theoretical foundation explaining its optimization dynamics is yet to be fully developed. In this study, we aim to bridge this understanding gap by answering the following two core questions: (1) Which types of Transformer architectures allow Gradient Descent (GD) to achieve guaranteed convergence? and (2) Under what initial conditions and architectural specifics does the Transformer achieve rapid convergence during training? By analyzing the loss landscape of a single Transformer layer using Softmax and Gaussian attention kernels, our work provides concrete answers to these questions. Our findings demonstrate that, with appropriate weight initialization, GD can train a Transformer model (with either kernel type) to achieve a global optimal solution, especially when the input embedding dimension is large. Nonetheless, certain scenarios highlight potential pitfalls: training a Transformer using the Softmax attention kernel may sometimes lead to suboptimal local solutions. In contrast, the Gaussian attention kernel exhibits a much favorable behavior. Our empirical study further validate the theoretical findings.
To Supervise or Not: How to Effectively Learn Wireless Interference Management Models?
Dec 28, 2021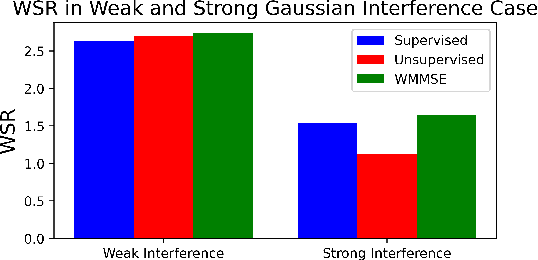
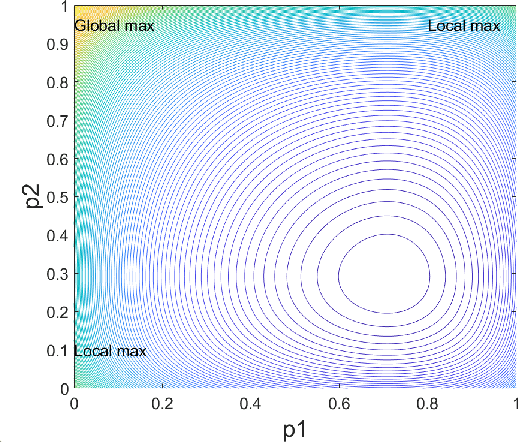
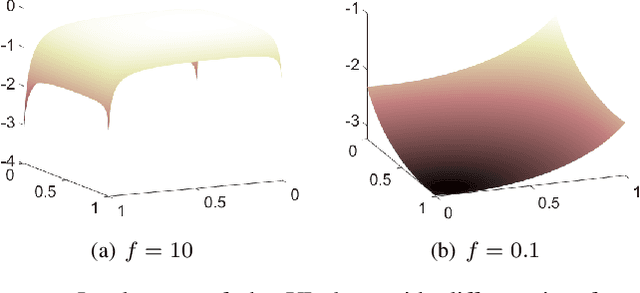
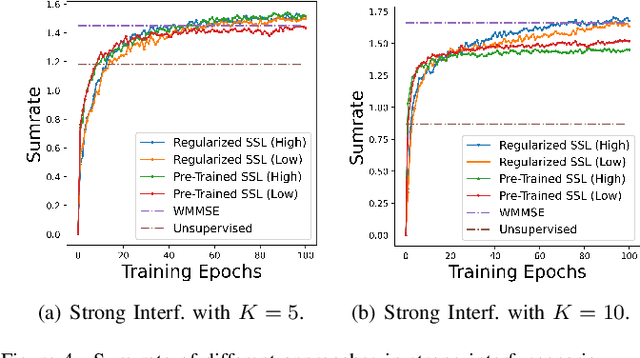
Machine learning has become successful in solving wireless interference management problems. Different kinds of deep neural networks (DNNs) have been trained to accomplish key tasks such as power control, beamforming and admission control. There are two popular training paradigms for such DNNs-based interference management models: supervised learning (i.e., fitting labels generated by an optimization algorithm) and unsupervised learning (i.e., directly optimizing some system performance measure). Although both of these paradigms have been extensively applied in practice, due to the lack of any theoretical understanding about these methods, it is not clear how to systematically understand and compare their performance. In this work, we conduct theoretical studies to provide some in-depth understanding about these two training paradigms. First, we show a somewhat surprising result, that for some special power control problem, the unsupervised learning can perform much worse than its supervised counterpart, because it is more likely to stuck at some low-quality local solutions. We then provide a series of theoretical results to further understand the properties of the two approaches. Generally speaking, we show that when high-quality labels are available, then the supervised learning is less likely to be stuck at a solution than its unsupervised counterpart. Additionally, we develop a semi-supervised learning approach which properly integrates these two training paradigms, and can effectively utilize limited number of labels to find high-quality solutions. To our knowledge, these are the first set of theoretical results trying to understand different training approaches in learning-based wireless communication system design.