 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Objects Matters in Weakly-supervised Semantic Segmentation
Sep 25, 2023Weakly-supervised semantic segmentation (WSSS) performs pixel-wise classification given only image-level labels for training. Despite the difficulty of this task, the research community has achieved promising results over the last five years. Still, current WSSS literature misses the detailed sense of how well the methods perform on different sizes of objects. Thus we propose a novel evaluation metric to provide a comprehensive assessment across different object sizes and collect a size-balanced evaluation set to complement PASCAL VOC. With these two gadgets, we reveal that the existing WSSS methods struggle in capturing small objects. Furthermore, we propose a size-balanced cross-entropy loss coupled with a proper training strategy. It generally improves existing WSSS methods as validated upon ten baselines on three different datasets.
D-Net: Learning for Distinctive Point Clouds by Self-Attentive Point Searching and Learnable Feature Fusion
May 10, 2023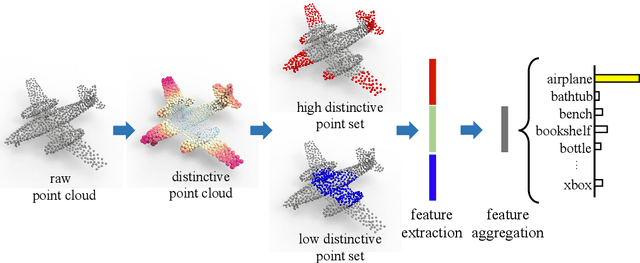
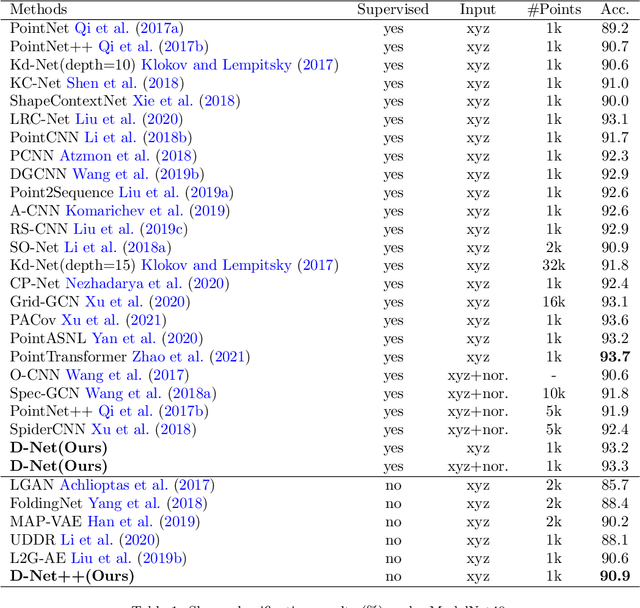
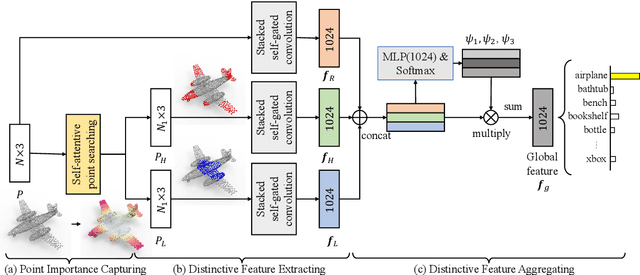
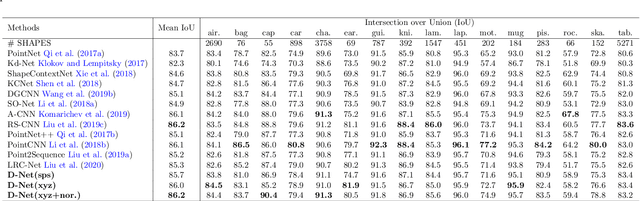
Learning and selecting important points on a point cloud is crucial for point cloud understanding in various applications. Most of early methods selected the important points on 3D shapes by analyzing the intrinsic geometric properties of every single shape, which fails to capture the importance of points that distinguishes a shape from objects of other classes, i.e., the distinction of points. To address this problem, we propose D-Net (Distinctive Network) to learn for distinctive point clouds based on a self-attentive point searching and a learnable feature fusion. Specifically, in the self-attentive point searching, we first learn the distinction score for each point to reveal the distinction distribution of the point cloud. After ranking the learned distinction scores, we group a point cloud into a high distinctive point set and a low distinctive one to enrich the fine-grained point cloud structure. To generate a compact feature representation for each distinctive point set, a stacked self-gated convolution is proposed to extract the distinctive features. Finally, we further introduce a learnable feature fusion mechanism to aggregate multiple distinctive features into a global point cloud representation in a channel-wise aggregation manner. The results also show that the learned distinction distribution of a point cloud is highly consistent with objects of the same class and different from objects of other classes. Extensive experiments on public datasets, including ModelNet and ShapeNet part dataset, demonstrate the ability to learn for distinctive point clouds, which helps to achieve the state-of-the-art performance in some shape understanding applications.