 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Shape Cues for Weakly Supervised Semantic Segmentation
Aug 08, 2022
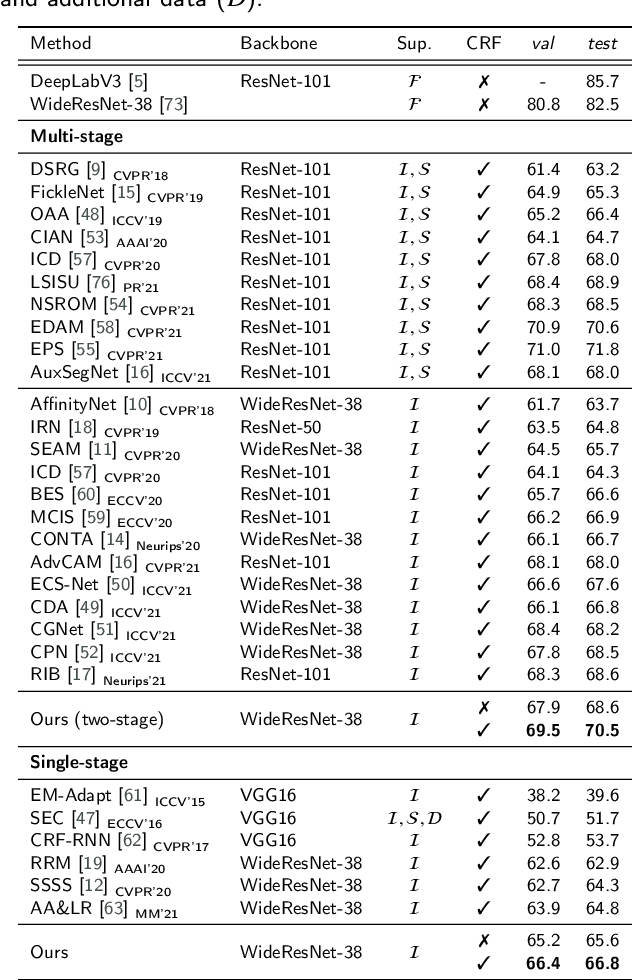
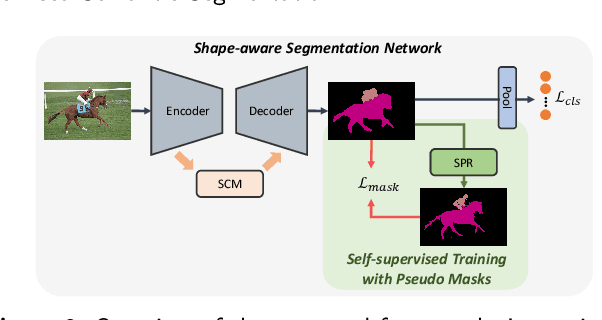
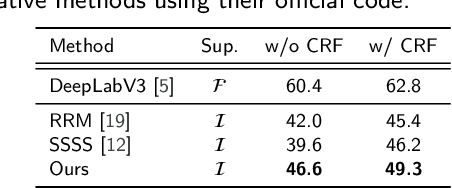
Weakly supervised semantic segmentation (WSSS) aims to produce pixel-wise class predictions with only image-level labels for training. To this end, previous methods adopt the common pipeline: they generate pseudo masks from class activation maps (CAMs) and use such masks to supervise segmentation networks. However, it is challenging to derive comprehensive pseudo masks that cover the whole extent of objects due to the local property of CAMs, i.e., they tend to focus solely on small discriminative object parts. In this paper, we associate the locality of CAMs with the texture-biased property of convolutional neural networks (CNNs). Accordingly, we propose to exploit shape information to supplement the texture-biased CNN features, thereby encouraging mask predictions to be not only comprehensive but also well-aligned with object boundaries. We further refine the predictions in an online fashion with a novel refinement method that takes into account both the class and the color affinities, in order to generate reliable pseudo masks to supervise the model. Importantly, our model is end-to-end trained within a single-stage framework and therefore efficient in terms of the training cost. Through extensive experiments on PASCAL VOC 2012, we validate the effectiveness of our method in producing precise and shape-aligned segmentation results. Specifically, our model surpasses the existing state-of-the-art single-stage approaches by large margins. What is more, it also achieves a new state-of-the-art performance over multi-stage approaches, when adopted in a simple two-stage pipeline without bells and whistles.
* Accepted by Pattern Recognition. The first two authors contributed equally
Cut and Continuous Paste towards Real-time Deep Fall Detection
Feb 22, 2022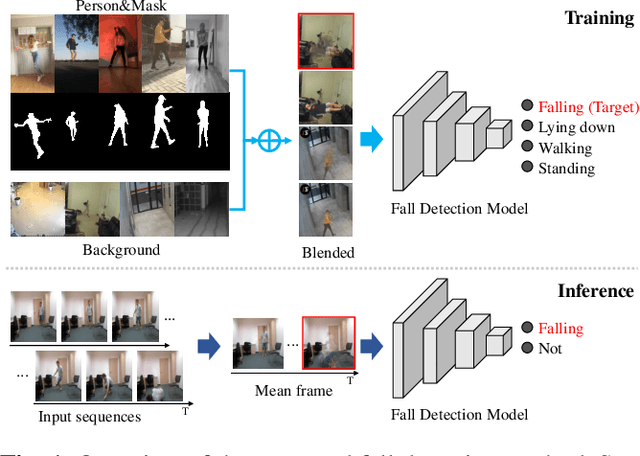
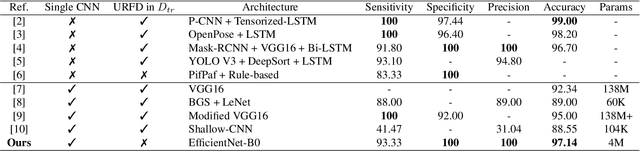

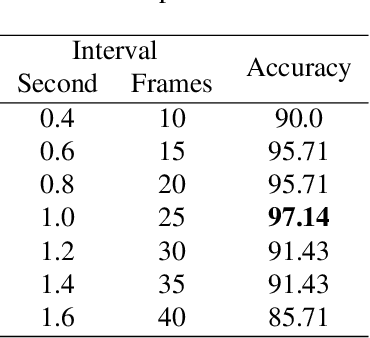
Deep learning based fall detection is one of the crucial tasks for intelligent video surveillance systems, which aims to detect unintentional falls of humans and alarm dangerous situations. In this work, we propose a simple and efficient framework to detect falls through a single and small-sized convolutional neural network. To this end, we first introduce a new image synthesis method that represents human motion in a single frame. This simplifies the fall detection task as an image classification task. Besides, the proposed synthetic data generation method enables to generate a sufficient amount of training dataset, resulting in satisfactory performance even with the small model. At the inference step, we also represent real human motion in a single image by estimating mean of input frames. In the experiment, we conduct both qualitative and quantitative evaluations on URFD and AIHub airport datasets to show the effectiveness of our method.
In-sample Contrastive Learning and Consistent Attention for Weakly Supervised Object Localization
Sep 25, 2020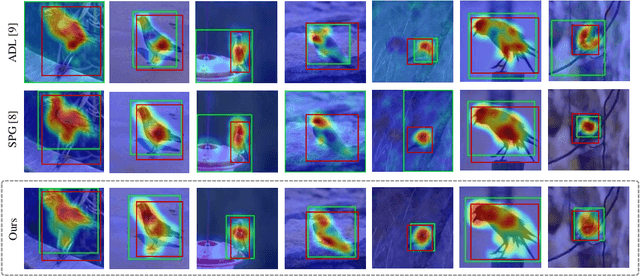
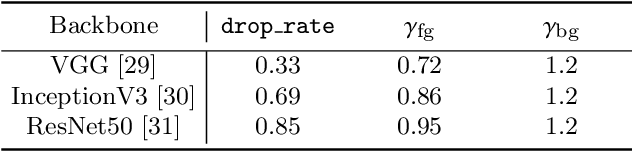
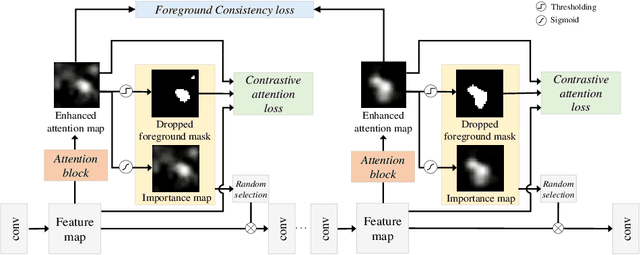
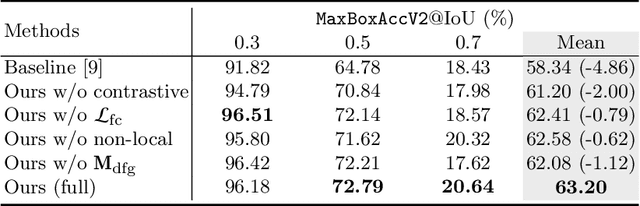
Weakly supervised object localization (WSOL) aims to localize the target object using only the image-level supervision. Recent methods encourage the model to activate feature maps over the entire object by dropping the most discriminative parts. However, they are likely to induce excessive extension to the backgrounds which leads to over-estimated localization. In this paper, we consider the background as an important cue that guides the feature activation to cover the sophisticated object region and propose contrastive attention loss. The loss promotes similarity between foreground and its dropped version, and, dissimilarity between the dropped version and background. Furthermore, we propose foreground consistency loss that penalizes earlier layers producing noisy attention regarding the later layer as a reference to provide them with a sense of backgroundness. It guides the early layers to activate on objects rather than locally distinctive backgrounds so that their attentions to be similar to the later layer. For better optimizing the above losses, we use the non-local attention blocks to replace channel-pooled attention leading to enhanced attention maps considering the spatial similarity. Last but not least, we propose to drop background regions in addition to the most discriminative region. Our method achieves state-of-theart performance on CUB-200-2011 and ImageNet benchmark datasets regarding top-1 localization accuracy and MaxBoxAccV2, and we provide detailed analysis on our individual components. The code will be publicly available online for reproducibility.