 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLKAVS: An Open Large-Scale Korean Audio-Visual Speech Dataset
Jan 16, 2023



Inspired by humans comprehending speech in a multi-modal manner, various audio-visual datasets have been constructed. However, most existing datasets focus on English, induce dependencies with various prediction models during dataset preparation, and have only a small number of multi-view videos. To mitigate the limitations, we recently developed the Open Large-scale Korean Audio-Visual Speech (OLKAVS) dataset, which is the largest among publicly available audio-visual speech datasets. The dataset contains 1,150 hours of transcribed audio from 1,107 Korean speakers in a studio setup with nine different viewpoints and various noise situations. We also provide the pre-trained baseline models for two tasks, audio-visual speech recognition and lip reading. We conducted experiments based on the models to verify the effectiveness of multi-modal and multi-view training over uni-modal and frontal-view-only training. We expect the OLKAVS dataset to facilitate multi-modal research in broader areas such as Korean speech recognition, speaker recognition, pronunciation level classification, and mouth motion analysis.
Cut and Continuous Paste towards Real-time Deep Fall Detection
Feb 22, 2022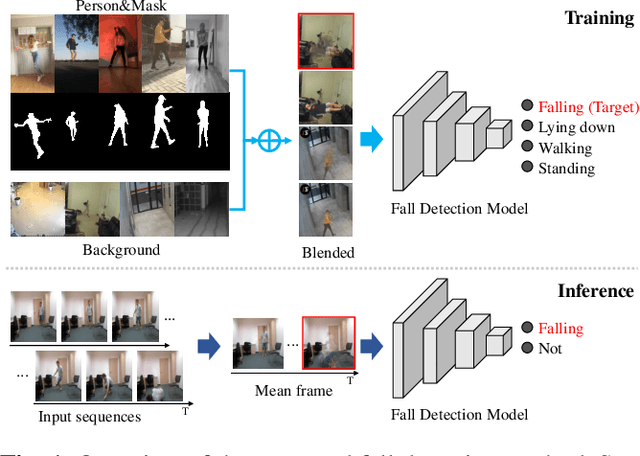
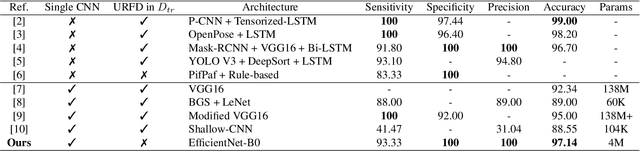

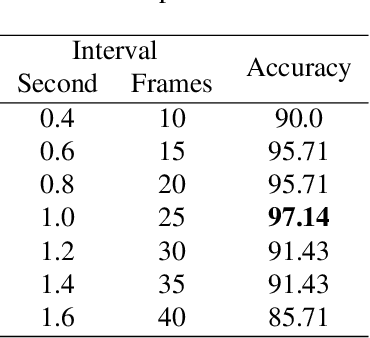
Deep learning based fall detection is one of the crucial tasks for intelligent video surveillance systems, which aims to detect unintentional falls of humans and alarm dangerous situations. In this work, we propose a simple and efficient framework to detect falls through a single and small-sized convolutional neural network. To this end, we first introduce a new image synthesis method that represents human motion in a single frame. This simplifies the fall detection task as an image classification task. Besides, the proposed synthetic data generation method enables to generate a sufficient amount of training dataset, resulting in satisfactory performance even with the small model. At the inference step, we also represent real human motion in a single image by estimating mean of input frames. In the experiment, we conduct both qualitative and quantitative evaluations on URFD and AIHub airport datasets to show the effectiveness of our method.
A Study on Stroke Rehabilitation through Task-Oriented Control of a Haptic Device via Near-Infrared Spectroscopy-Based BCI
Apr 14, 2014

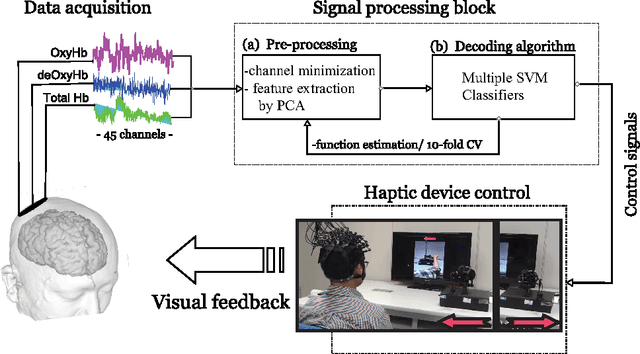
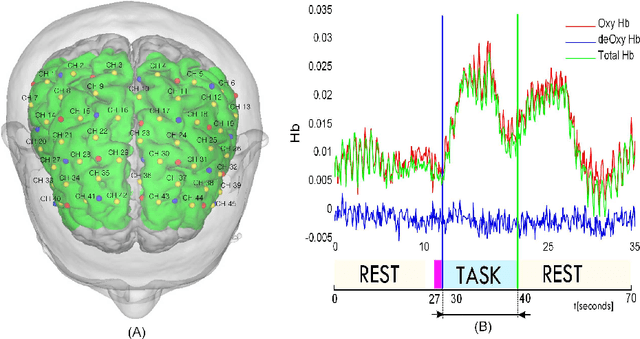
This paper presents a study in task-oriented approach to stroke rehabilitation by controlling a haptic device via near-infrared spectroscopy-based brain-computer interface (BCI). The task is to command the haptic device to move in opposing directions of leftward and rightward movement. Our study consists of data acquisition, signal preprocessing, and classification. In data acquisition, we conduct experiments based on two different mental tasks: one on pure motor imagery, and another on combined motor imagery and action observation. The experiments were conducted in both offline and online modes. In the signal preprocessing, we use localization method to eliminate channels that are irrelevant to the mental task, as well as perform feature extraction for subsequent classification. We propose multiple support vector machine classifiers with a majority-voting scheme for improved classification results. And lastly, we present test results to demonstrate the efficacy of our proposed approach to possible stroke rehabilitation practice.
Minimizing inter-subject variability in fNIRS based Brain Computer Interfaces via multiple-kernel support vector learning
May 08, 2013Brain signal variability in the measurements obtained from different subjects during different sessions significantly deteriorates the accuracy of most brain-computer interface (BCI) systems. Moreover these variabilities, also known as inter-subject or inter-session variabilities, require lengthy calibration sessions before the BCI system can be used. Furthermore, the calibration session has to be repeated for each subject independently and before use of the BCI due to the inter-session variability. In this study, we present an algorithm in order to minimize the above-mentioned variabilities and to overcome the time-consuming and usually error-prone calibration time. Our algorithm is based on linear programming support-vector machines and their extensions to a multiple kernel learning framework. We tackle the inter-subject or -session variability in the feature spaces of the classifiers. This is done by incorporating each subject- or session-specific feature spaces into much richer feature spaces with a set of optimal decision boundaries. Each decision boundary represents the subject- or a session specific spatio-temporal variabilities of neural signals. Consequently, a single classifier with multiple feature spaces will generalize well to new unseen test patterns even without the calibration steps. We demonstrate that classifiers maintain good performances even under the presence of a large degree of BCI variability. The present study analyzes BCI variability related to oxy-hemoglobin neural signals measured using a functional near-infrared spectroscopy.