 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Speech Representation Pooling Using Vector Quantization
Apr 08, 2023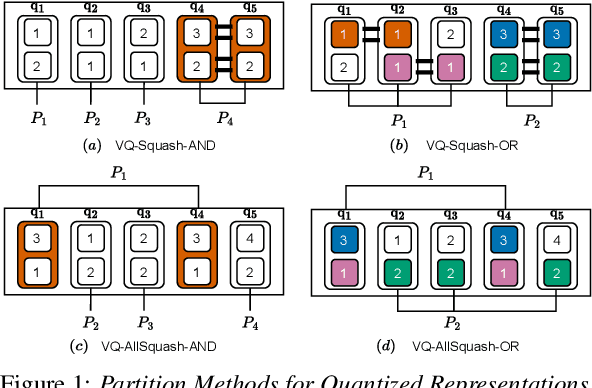
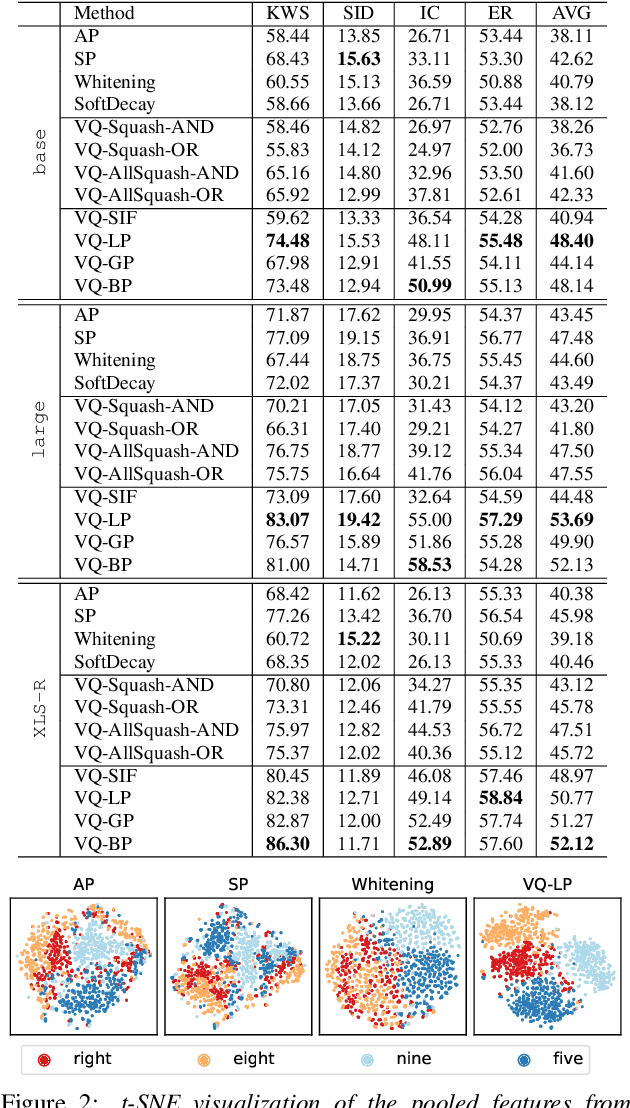
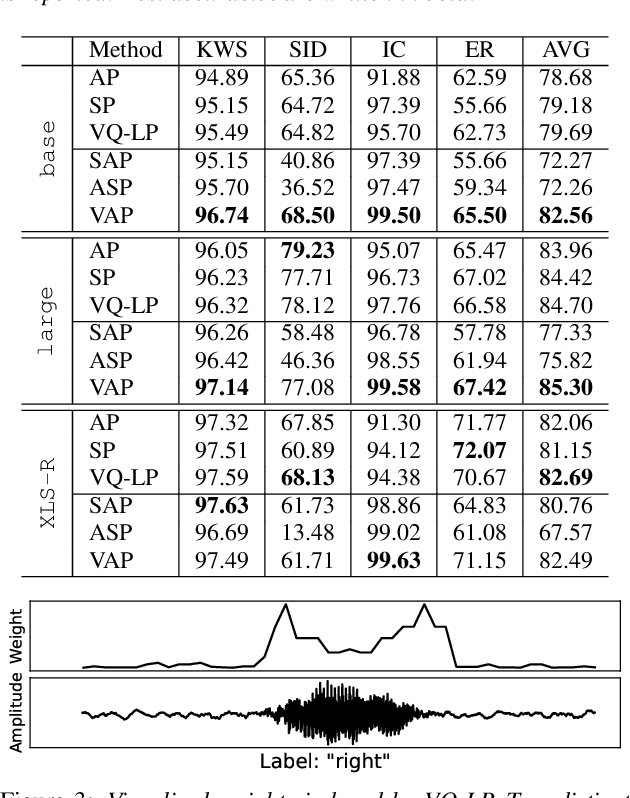
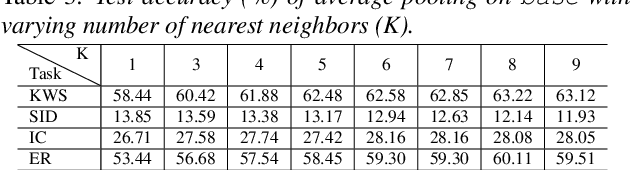
With the advent of general-purpose speech representations from large-scale self-supervised models, applying a single model to multiple downstream tasks is becoming a de-facto approach. However, the pooling problem remains; the length of speech representations is inherently variable. The naive average pooling is often used, even though it ignores the characteristics of speech, such as differently lengthed phonemes. Hence, we design a novel pooling method to squash acoustically similar representations via vector quantization, which does not require additional training, unlike attention-based pooling. Further, we evaluate various unsupervised pooling methods on various self-supervised models. We gather diverse methods scattered around speech and text to evaluate on various tasks: keyword spotting, speaker identification, intent classification, and emotion recognition. Finally, we quantitatively and qualitatively analyze our method, comparing it with supervised pooling methods.
OLKAVS: An Open Large-Scale Korean Audio-Visual Speech Dataset
Jan 16, 2023



Inspired by humans comprehending speech in a multi-modal manner, various audio-visual datasets have been constructed. However, most existing datasets focus on English, induce dependencies with various prediction models during dataset preparation, and have only a small number of multi-view videos. To mitigate the limitations, we recently developed the Open Large-scale Korean Audio-Visual Speech (OLKAVS) dataset, which is the largest among publicly available audio-visual speech datasets. The dataset contains 1,150 hours of transcribed audio from 1,107 Korean speakers in a studio setup with nine different viewpoints and various noise situations. We also provide the pre-trained baseline models for two tasks, audio-visual speech recognition and lip reading. We conducted experiments based on the models to verify the effectiveness of multi-modal and multi-view training over uni-modal and frontal-view-only training. We expect the OLKAVS dataset to facilitate multi-modal research in broader areas such as Korean speech recognition, speaker recognition, pronunciation level classification, and mouth motion analysis.