 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWritingBench: A Comprehensive Benchmark for Generative Writing
Mar 07, 2025Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
StyleMamba : State Space Model for Efficient Text-driven Image Style Transfer
May 08, 2024We present StyleMamba, an efficient image style transfer framework that translates text prompts into corresponding visual styles while preserving the content integrity of the original images. Existing text-guided stylization requires hundreds of training iterations and takes a lot of computing resources. To speed up the process, we propose a conditional State Space Model for Efficient Text-driven Image Style Transfer, dubbed StyleMamba, that sequentially aligns the image features to the target text prompts. To enhance the local and global style consistency between text and image, we propose masked and second-order directional losses to optimize the stylization direction to significantly reduce the training iterations by 5 times and the inference time by 3 times. Extensive experiments and qualitative evaluation confirm the robust and superior stylization performance of our methods compared to the existing baselines.
Uncertainty-aware self-training with expectation maximization basis transformation
May 02, 2024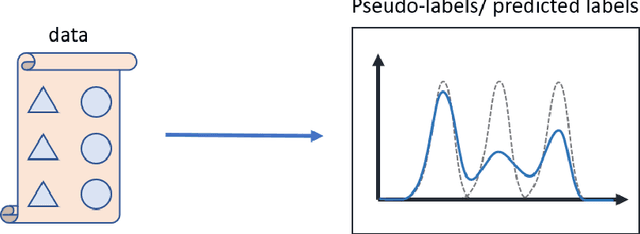



Self-training is a powerful approach to deep learning. The key process is to find a pseudo-label for modeling. However, previous self-training algorithms suffer from the over-confidence issue brought by the hard labels, even some confidence-related regularizers cannot comprehensively catch the uncertainty. Therefore, we propose a new self-training framework to combine uncertainty information of both model and dataset. Specifically, we propose to use Expectation-Maximization (EM) to smooth the labels and comprehensively estimate the uncertainty information. We further design a basis extraction network to estimate the initial basis from the dataset. The obtained basis with uncertainty can be filtered based on uncertainty information. It can then be transformed into the real hard label to iteratively update the model and basis in the retraining process. Experiments on image classification and semantic segmentation show the advantages of our methods among confidence-aware self-training algorithms with 1-3 percentage improvement on different datasets.
Potential Energy based Mixture Model for Noisy Label Learning
May 02, 2024



Training deep neural networks (DNNs) from noisy labels is an important and challenging task. However, most existing approaches focus on the corrupted labels and ignore the importance of inherent data structure. To bridge the gap between noisy labels and data, inspired by the concept of potential energy in physics, we propose a novel Potential Energy based Mixture Model (PEMM) for noise-labels learning. We innovate a distance-based classifier with the potential energy regularization on its class centers. Embedding our proposed classifier with existing deep learning backbones, we can have robust networks with better feature representations. They can preserve intrinsic structures from the data, resulting in a superior noisy tolerance. We conducted extensive experiments to analyze the efficiency of our proposed model on several real-world datasets. Quantitative results show that it can achieve state-of-the-art performance.
Arbitrary point cloud upsampling via Dual Back-Projection Network
Jul 18, 2023



Point clouds acquired from 3D sensors are usually sparse and noisy. Point cloud upsampling is an approach to increase the density of the point cloud so that detailed geometric information can be restored. In this paper, we propose a Dual Back-Projection network for point cloud upsampling (DBPnet). A Dual Back-Projection is formulated in an up-down-up manner for point cloud upsampling. It not only back projects feature residues but also coordinates residues so that the network better captures the point correlations in the feature and space domains, achieving lower reconstruction errors on both uniform and non-uniform sparse point clouds. Our proposed method is also generalizable for arbitrary upsampling tasks (e.g. 4x, 5.5x). Experimental results show that the proposed method achieves the lowest point set matching losses with respect to the benchmark. In addition, the success of our approach demonstrates that generative networks are not necessarily needed for non-uniform point clouds.
* 5 pages, 5 figures
Soft-IntroVAE for Continuous Latent space Image Super-Resolution
Jul 18, 2023Continuous image super-resolution (SR) recently receives a lot of attention from researchers, for its practical and flexible image scaling for various displays. Local implicit image representation is one of the methods that can map the coordinates and 2D features for latent space interpolation. Inspired by Variational AutoEncoder, we propose a Soft-introVAE for continuous latent space image super-resolution (SVAE-SR). A novel latent space adversarial training is achieved for photo-realistic image restoration. To further improve the quality, a positional encoding scheme is used to extend the original pixel coordinates by aggregating frequency information over the pixel areas. We show the effectiveness of the proposed SVAE-SR through quantitative and qualitative comparisons, and further, illustrate its generalization in denoising and real-image super-resolution.
* 5 pages, 4 figures