 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware self-training with expectation maximization basis transformation
Paper and Code
May 02, 2024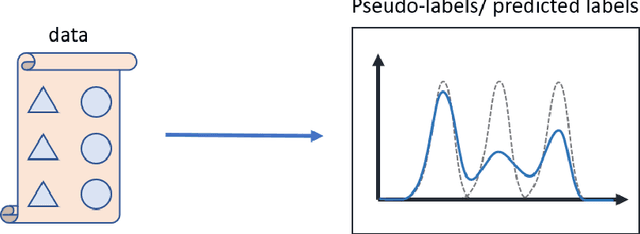



Self-training is a powerful approach to deep learning. The key process is to find a pseudo-label for modeling. However, previous self-training algorithms suffer from the over-confidence issue brought by the hard labels, even some confidence-related regularizers cannot comprehensively catch the uncertainty. Therefore, we propose a new self-training framework to combine uncertainty information of both model and dataset. Specifically, we propose to use Expectation-Maximization (EM) to smooth the labels and comprehensively estimate the uncertainty information. We further design a basis extraction network to estimate the initial basis from the dataset. The obtained basis with uncertainty can be filtered based on uncertainty information. It can then be transformed into the real hard label to iteratively update the model and basis in the retraining process. Experiments on image classification and semantic segmentation show the advantages of our methods among confidence-aware self-training algorithms with 1-3 percentage improvement on different datasets.