 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcavate the potential of Single-Scale Features: A Decomposition Network for Water-Related Optical Image Enhancement
Aug 06, 2025Underwater image enhancement (UIE) techniques aim to improve visual quality of images captured in aquatic environments by addressing degradation issues caused by light absorption and scattering effects, including color distortion, blurring, and low contrast. Current mainstream solutions predominantly employ multi-scale feature extraction (MSFE) mechanisms to enhance reconstruction quality through multi-resolution feature fusion. However, our extensive experiments demonstrate that high-quality image reconstruction does not necessarily rely on multi-scale feature fusion. Contrary to popular belief, our experiments show that single-scale feature extraction alone can match or surpass the performance of multi-scale methods, significantly reducing complexity. To comprehensively explore single-scale feature potential in underwater enhancement, we propose an innovative Single-Scale Decomposition Network (SSD-Net). This architecture introduces an asymmetrical decomposition mechanism that disentangles input image into clean layer along with degradation layer. The former contains scene-intrinsic information and the latter encodes medium-induced interference. It uniquely combines CNN's local feature extraction capabilities with Transformer's global modeling strengths through two core modules: 1) Parallel Feature Decomposition Block (PFDB), implementing dual-branch feature space decoupling via efficient attention operations and adaptive sparse transformer; 2) Bidirectional Feature Communication Block (BFCB), enabling cross-layer residual interactions for complementary feature mining and fusion. This synergistic design preserves feature decomposition independence while establishing dynamic cross-layer information pathways, effectively enhancing degradation decoupling capacity.
Cellular Automaton With CNN
Mar 04, 2025Cellular automata (CA) models are widely used to simulate complex systems with emergent behaviors, but identifying hidden parameters that govern their dynamics remains a significant challenge. This study explores the use of Convolutional Neural Networks (CNN) to identify jump parameters in a two-dimensional CA model. We propose a custom CNN architecture trained on CA-generated data to classify jump parameters, which dictates the neighborhood size and movement rules of cells within the CA. Experiments were conducted across varying domain sizes (25 x 25 to 150 x 150) and CA iterations (0 to 50), demonstrating that the accuracy improves with larger domain sizes, as they provide more spatial information for parameter estimation. Interestingly, while initial CA iterations enhance the performance, increasing the number of iterations beyond a certain threshold does not significantly improve accuracy, suggesting that only specific temporal information is relevant for parameter identification. The proposed CNN achieves competitive accuracy (89.31) compared to established architectures like LeNet-5 and AlexNet, while offering significantly faster inference times, making it suitable for real-time applications. This study highlights the potential of CNNs as a powerful tool for fast and accurate parameter estimation in CA models, paving the way for their use in more complex systems and higher-dimensional domains. Future work will explore the identification of multiple hidden parameters and extend the approach to three-dimensional CA models.
Uncertainty-aware self-training with expectation maximization basis transformation
May 02, 2024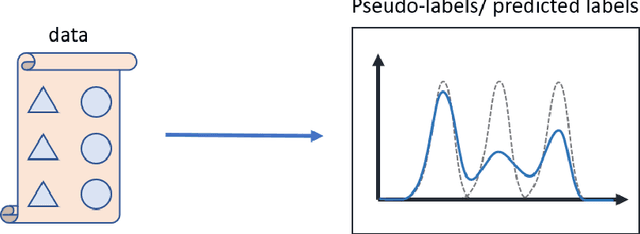



Self-training is a powerful approach to deep learning. The key process is to find a pseudo-label for modeling. However, previous self-training algorithms suffer from the over-confidence issue brought by the hard labels, even some confidence-related regularizers cannot comprehensively catch the uncertainty. Therefore, we propose a new self-training framework to combine uncertainty information of both model and dataset. Specifically, we propose to use Expectation-Maximization (EM) to smooth the labels and comprehensively estimate the uncertainty information. We further design a basis extraction network to estimate the initial basis from the dataset. The obtained basis with uncertainty can be filtered based on uncertainty information. It can then be transformed into the real hard label to iteratively update the model and basis in the retraining process. Experiments on image classification and semantic segmentation show the advantages of our methods among confidence-aware self-training algorithms with 1-3 percentage improvement on different datasets.
Potential Energy based Mixture Model for Noisy Label Learning
May 02, 2024



Training deep neural networks (DNNs) from noisy labels is an important and challenging task. However, most existing approaches focus on the corrupted labels and ignore the importance of inherent data structure. To bridge the gap between noisy labels and data, inspired by the concept of potential energy in physics, we propose a novel Potential Energy based Mixture Model (PEMM) for noise-labels learning. We innovate a distance-based classifier with the potential energy regularization on its class centers. Embedding our proposed classifier with existing deep learning backbones, we can have robust networks with better feature representations. They can preserve intrinsic structures from the data, resulting in a superior noisy tolerance. We conducted extensive experiments to analyze the efficiency of our proposed model on several real-world datasets. Quantitative results show that it can achieve state-of-the-art performance.