 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecast-PEFT: Parameter-Efficient Fine-Tuning for Pre-trained Motion Forecasting Models
Jul 28, 2024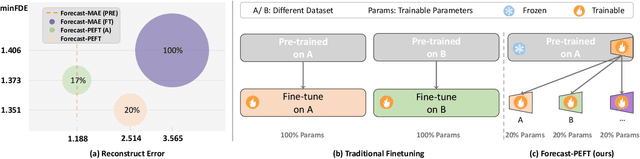
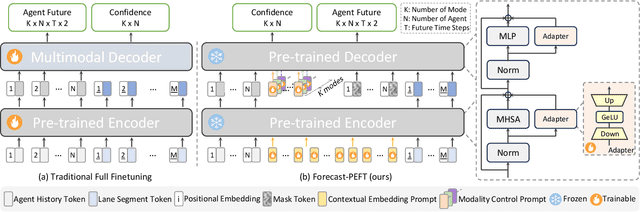
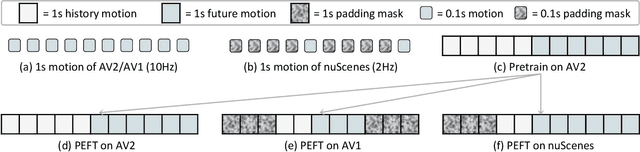
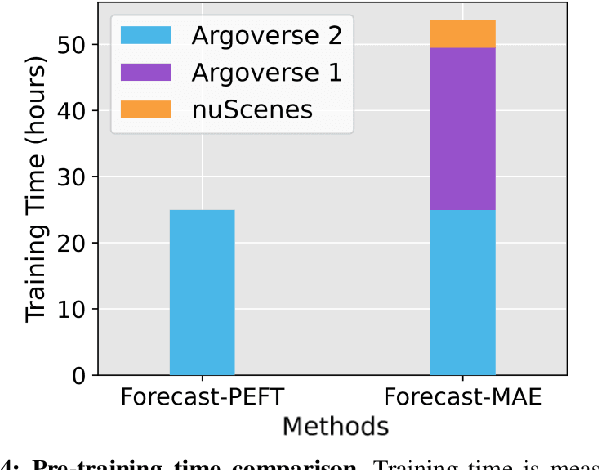
Recent progress in motion forecasting has been substantially driven by self-supervised pre-training. However, adapting pre-trained models for specific downstream tasks, especially motion prediction, through extensive fine-tuning is often inefficient. This inefficiency arises because motion prediction closely aligns with the masked pre-training tasks, and traditional full fine-tuning methods fail to fully leverage this alignment. To address this, we introduce Forecast-PEFT, a fine-tuning strategy that freezes the majority of the model's parameters, focusing adjustments on newly introduced prompts and adapters. This approach not only preserves the pre-learned representations but also significantly reduces the number of parameters that need retraining, thereby enhancing efficiency. This tailored strategy, supplemented by our method's capability to efficiently adapt to different datasets, enhances model efficiency and ensures robust performance across datasets without the need for extensive retraining. Our experiments show that Forecast-PEFT outperforms traditional full fine-tuning methods in motion prediction tasks, achieving higher accuracy with only 17% of the trainable parameters typically required. Moreover, our comprehensive adaptation, Forecast-FT, further improves prediction performance, evidencing up to a 9.6% enhancement over conventional baseline methods. Code will be available at https://github.com/csjfwang/Forecast-PEFT.
Stacked Conditional Generative Adversarial Networks for Jointly Learning Shadow Detection and Shadow Removal
Dec 07, 2017



Understanding shadows from a single image spontaneously derives into two types of task in previous studies, containing shadow detection and shadow removal. In this paper, we present a multi-task perspective, which is not embraced by any existing work, to jointly learn both detection and removal in an end-to-end fashion that aims at enjoying the mutually improved benefits from each other. Our framework is based on a novel STacked Conditional Generative Adversarial Network (ST-CGAN), which is composed of two stacked CGANs, each with a generator and a discriminator. Specifically, a shadow image is fed into the first generator which produces a shadow detection mask. That shadow image, concatenated with its predicted mask, goes through the second generator in order to recover its shadow-free image consequently. In addition, the two corresponding discriminators are very likely to model higher level relationships and global scene characteristics for the detected shadow region and reconstruction via removing shadows, respectively. More importantly, for multi-task learning, our design of stacked paradigm provides a novel view which is notably different from the commonly used one as the multi-branch version. To fully evaluate the performance of our proposed framework, we construct the first large-scale benchmark with 1870 image triplets (shadow image, shadow mask image, and shadow-free image) under 135 scenes. Extensive experimental results consistently show the advantages of ST-CGAN over several representative state-of-the-art methods on two large-scale publicly available datasets and our newly released one.