 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairCLIPv2: Unifying Hair Editing via Proxy Feature Blending
Paper and Code

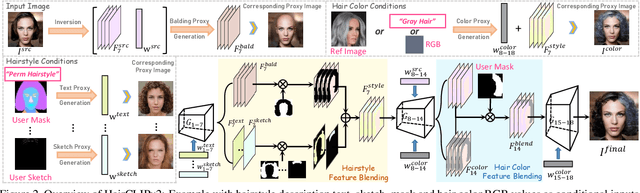


Hair editing has made tremendous progress in recent years. Early hair editing methods use well-drawn sketches or masks to specify the editing conditions. Even though they can enable very fine-grained local control, such interaction modes are inefficient for the editing conditions that can be easily specified by language descriptions or reference images. Thanks to the recent breakthrough of cross-modal models (e.g., CLIP), HairCLIP is the first work that enables hair editing based on text descriptions or reference images. However, such text-driven and reference-driven interaction modes make HairCLIP unable to support fine-grained controls specified by sketch or mask. In this paper, we propose HairCLIPv2, aiming to support all the aforementioned interactions with one unified framework. Simultaneously, it improves upon HairCLIP with better irrelevant attributes (e.g., identity, background) preservation and unseen text descriptions support. The key idea is to convert all the hair editing tasks into hair transfer tasks, with editing conditions converted into different proxies accordingly. The editing effects are added upon the input image by blending the corresponding proxy features within the hairstyle or hair color feature spaces. Besides the unprecedented user interaction mode support, quantitative and qualitative experiments demonstrate the superiority of HairCLIPv2 in terms of editing effects, irrelevant attribute preservation and visual naturalness. Our code is available at \url{https://github.com/wty-ustc/HairCLIPv2}.