 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizers for Single-step Adversarial Training
Feb 03, 2020



The progress in the last decade has enabled machine learning models to achieve impressive performance across a wide range of tasks in Computer Vision. However, a plethora of works have demonstrated the susceptibility of these models to adversarial samples. Adversarial training procedure has been proposed to defend against such adversarial attacks. Adversarial training methods augment mini-batches with adversarial samples, and typically single-step (non-iterative) methods are used for generating these adversarial samples. However, models trained using single-step adversarial training converge to degenerative minima where the model merely appears to be robust. The pseudo robustness of these models is due to the gradient masking effect. Although multi-step adversarial training helps to learn robust models, they are hard to scale due to the use of iterative methods for generating adversarial samples. To address these issues, we propose three different types of regularizers that help to learn robust models using single-step adversarial training methods. The proposed regularizers mitigate the effect of gradient masking by harnessing on properties that differentiate a robust model from that of a pseudo robust model. Performance of models trained using the proposed regularizers is on par with models trained using computationally expensive multi-step adversarial training methods.
FDA: Feature Disruptive Attack
Sep 10, 2019
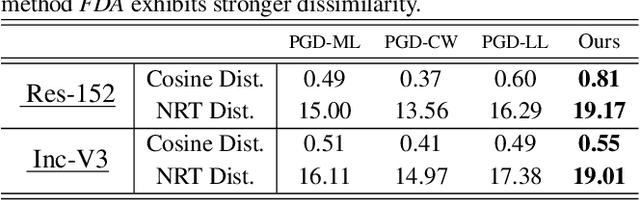
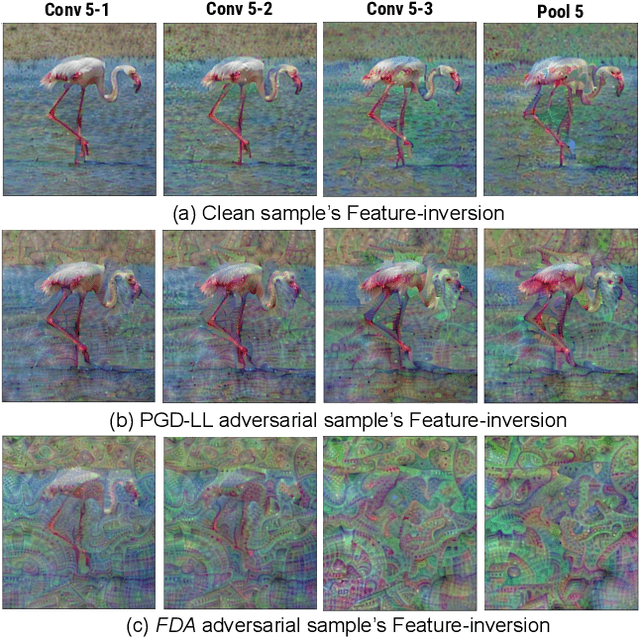
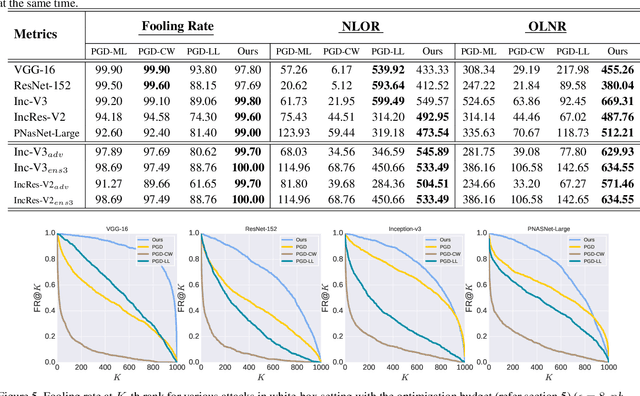
Though Deep Neural Networks (DNN) show excellent performance across various computer vision tasks, several works show their vulnerability to adversarial samples, i.e., image samples with imperceptible noise engineered to manipulate the network's prediction. Adversarial sample generation methods range from simple to complex optimization techniques. Majority of these methods generate adversaries through optimization objectives that are tied to the pre-softmax or softmax output of the network. In this work we, (i) show the drawbacks of such attacks, (ii) propose two new evaluation metrics: Old Label New Rank (OLNR) and New Label Old Rank (NLOR) in order to quantify the extent of damage made by an attack, and (iii) propose a new adversarial attack FDA: Feature Disruptive Attack, to address the drawbacks of existing attacks. FDA works by generating image perturbation that disrupt features at each layer of the network and causes deep-features to be highly corrupt. This allows FDA adversaries to severely reduce the performance of deep networks. We experimentally validate that FDA generates stronger adversaries than other state-of-the-art methods for image classification, even in the presence of various defense measures. More importantly, we show that FDA disrupts feature-representation based tasks even without access to the task-specific network or methodology. Code available at: https://github.com/BardOfCodes/fda