Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Extractors for Music Source Separation
Paper and Code


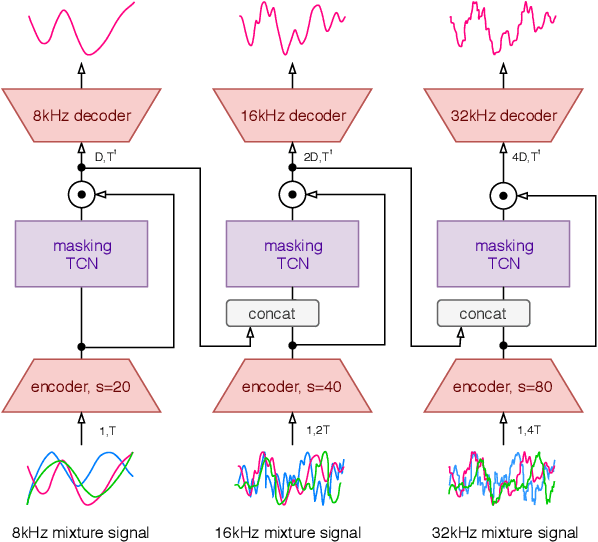

We propose a hierarchical meta-learning-inspired model for music source separation (Meta-TasNet) in which a generator model is used to predict the weights of individual extractor models. This enables efficient parameter-sharing, while still allowing for instrument-specific parameterization. Meta-TasNet is shown to be more effective than the models trained independently or in a multi-task setting, and achieve performance comparable with state-of-the-art methods. In comparison to the latter, our extractors contain fewer parameters and have faster run-time performance. We discuss important architectural considerations, and explore the costs and benefits of this approach.
* Camera-ready version for ICASSP 2020; the source files are published
at https://github.com/pfnet-research/meta-tasnet
View paper on