 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Pose Estimation from Monocular Image using Multi-View Keypoint Correspondence
Sep 03, 2018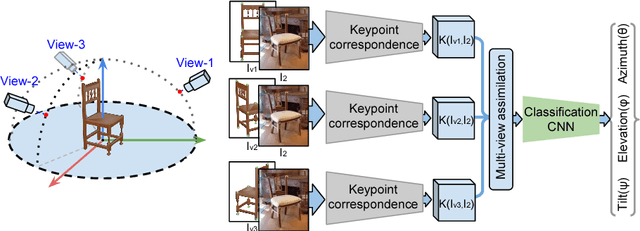

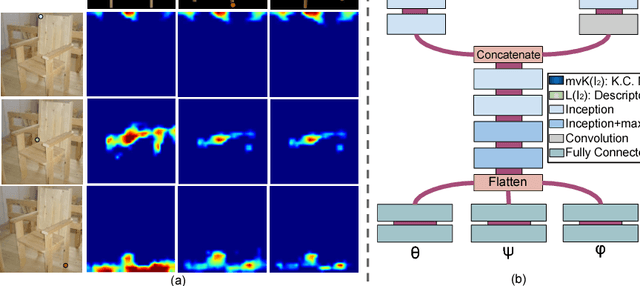
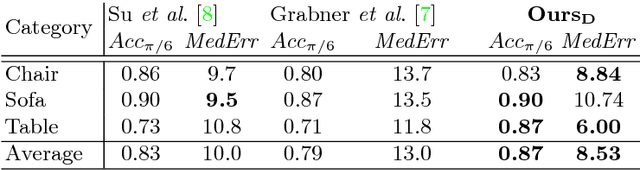
Understanding the geometry and pose of objects in 2D images is a fundamental necessity for a wide range of real world applications. Driven by deep neural networks, recent methods have brought significant improvements to object pose estimation. However, they suffer due to scarcity of keypoint/pose-annotated real images and hence can not exploit the object's 3D structural information effectively. In this work, we propose a data-efficient method which utilizes the geometric regularity of intraclass objects for pose estimation. First, we learn pose-invariant local descriptors of object parts from simple 2D RGB images. These descriptors, along with keypoints obtained from renders of a fixed 3D template model are then used to generate keypoint correspondence maps for a given monocular real image. Finally, a pose estimation network predicts 3D pose of the object using these correspondence maps. This pipeline is further extended to a multi-view approach, which assimilates keypoint information from correspondence sets generated from multiple views of the 3D template model. Fusion of multi-view information significantly improves geometric comprehension of the system which in turn enhances the pose estimation performance. Furthermore, use of correspondence framework responsible for the learning of pose invariant keypoint descriptor also allows us to effectively alleviate the data-scarcity problem. This enables our method to achieve state-of-the-art performance on multiple real-image viewpoint estimation datasets, such as Pascal3D+ and ObjectNet3D. To encourage reproducible research, we have released the codes for our proposed approach.
iSPA-Net: Iterative Semantic Pose Alignment Network
Aug 03, 2018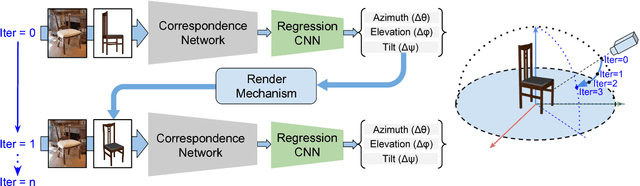
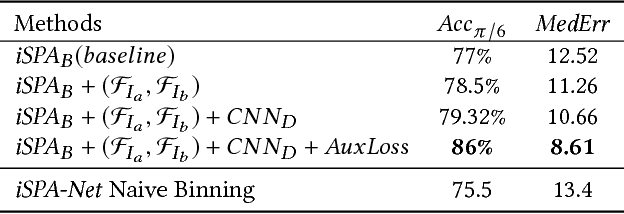
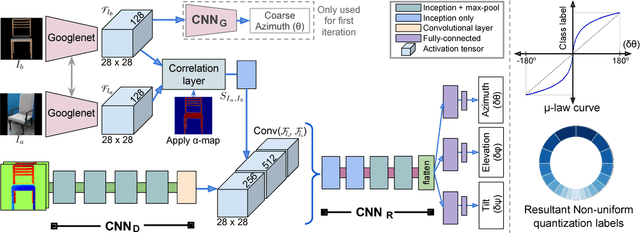
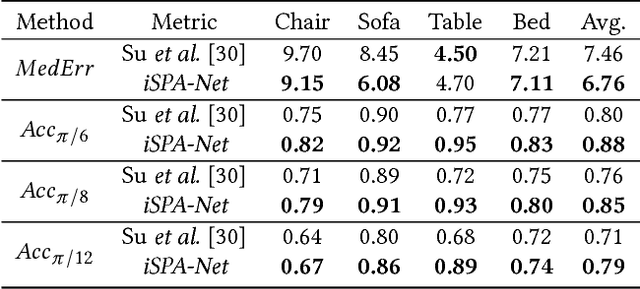
Understanding and extracting 3D information of objects from monocular 2D images is a fundamental problem in computer vision. In the task of 3D object pose estimation, recent data driven deep neural network based approaches suffer from scarcity of real images with 3D keypoint and pose annotations. Drawing inspiration from human cognition, where the annotators use a 3D CAD model as structural reference to acquire ground-truth viewpoints for real images; we propose an iterative Semantic Pose Alignment Network, called iSPA-Net. Our approach focuses on exploiting semantic 3D structural regularity to solve the task of fine-grained pose estimation by predicting viewpoint difference between a given pair of images. Such image comparison based approach also alleviates the problem of data scarcity and hence enhances scalability of the proposed approach for novel object categories with minimal annotation. The fine-grained object pose estimator is also aided by correspondence of learned spatial descriptor of the input image pair. The proposed pose alignment framework enjoys the faculty to refine its initial pose estimation in consecutive iterations by utilizing an online rendering setup along with effectiveness of a non-uniform bin classification of pose-difference. This enables iSPA-Net to achieve state-of-the-art performance on various real image viewpoint estimation datasets. Further, we demonstrate effectiveness of the approach for multiple applications. First, we show results for active object viewpoint localization to capture images from similar pose considering only a single image as pose reference. Second, we demonstrate the ability of the learned semantic correspondence to perform unsupervised part-segmentation transfer using only a single part-annotated 3D template model per object class. To encourage reproducible research, we have released the codes for our proposed algorithm.