 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplex Dirichlet stochastic block model for clustering multidimensional compositional networks
Dec 16, 2024Network data often represent multiple types of relations, which can also denote exchanged quantities, and are typically encompassed in a weighted multiplex. Such data frequently exhibit clustering structures, however, traditional clustering methods are not well-suited for multiplex networks. Additionally, standard methods treat edge weights in their raw form, potentially biasing clustering towards a node's total weight capacity rather than reflecting cluster-related interaction patterns. To address this, we propose transforming edge weights into a compositional format, enabling the analysis of connection strengths in relative terms and removing the impact of nodes' total weights. We introduce a multiplex Dirichlet stochastic block model designed for multiplex networks with compositional layers. This model accounts for sparse compositional networks and enables joint clustering across different types of interactions. We validate the model through a simulation study and apply it to the international export data from the Food and Agriculture Organization of the United Nations.
A Dirichlet stochastic block model for composition-weighted networks
Aug 01, 2024Network data are observed in various applications where the individual entities of the system interact with or are connected to each other, and often these interactions are defined by their associated strength or importance. Clustering is a common task in network analysis that involves finding groups of nodes displaying similarities in the way they interact with the rest of the network. However, most clustering methods use the strengths of connections between entities in their original form, ignoring the possible differences in the capacities of individual nodes to send or receive edges. This often leads to clustering solutions that are heavily influenced by the nodes' capacities. One way to overcome this is to analyse the strengths of connections in relative rather than absolute terms, expressing each edge weight as a proportion of the sending (or receiving) capacity of the respective node. This, however, induces additional modelling constraints that most existing clustering methods are not designed to handle. In this work we propose a stochastic block model for composition-weighted networks based on direct modelling of compositional weight vectors using a Dirichlet mixture, with the parameters determined by the cluster labels of the sender and the receiver nodes. Inference is implemented via an extension of the classification expectation-maximisation algorithm that uses a working independence assumption, expressing the complete data likelihood of each node of the network as a function of fixed cluster labels of the remaining nodes. A model selection criterion is derived to aid the choice of the number of clusters. The model is validated using simulation studies, and showcased on network data from the Erasmus exchange program and a bike sharing network for the city of London.
A consensus-constrained parsimonious Gaussian mixture model for clustering hyperspectral images
Mar 05, 2024The use of hyperspectral imaging to investigate food samples has grown due to the improved performance and lower cost of spectroscopy instrumentation. Food engineers use hyperspectral images to classify the type and quality of a food sample, typically using classification methods. In order to train these methods, every pixel in each training image needs to be labelled. Typically, computationally cheap threshold-based approaches are used to label the pixels, and classification methods are trained based on those labels. However, threshold-based approaches are subjective and cannot be generalized across hyperspectral images taken in different conditions and of different foods. Here a consensus-constrained parsimonious Gaussian mixture model (ccPGMM) is proposed to label pixels in hyperspectral images using a model-based clustering approach. The ccPGMM utilizes available information on the labels of a small number of pixels and the relationship between those pixels and neighbouring pixels as constraints when clustering the rest of the pixels in the image. A latent variable model is used to represent the high-dimensional data in terms of a small number of underlying latent factors. To ensure computational feasibility, a consensus clustering approach is employed, where the data are divided into multiple randomly selected subsets of variables and constrained clustering is applied to each data subset; the clustering results are then consolidated across all data subsets to provide a consensus clustering solution. The ccPGMM approach is applied to simulated datasets and real hyperspectral images of three types of puffed cereal, corn, rice, and wheat. Improved clustering performance and computational efficiency are demonstrated when compared to other current state-of-the-art approaches.
Unobserved classes and extra variables in high-dimensional discriminant analysis
Feb 03, 2021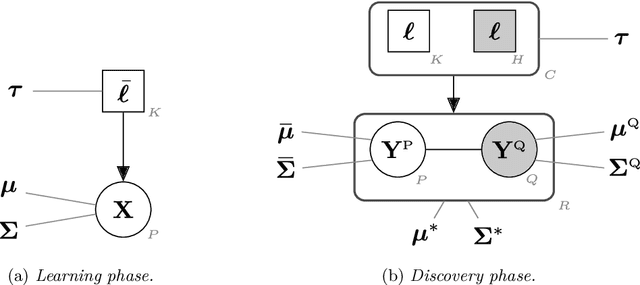
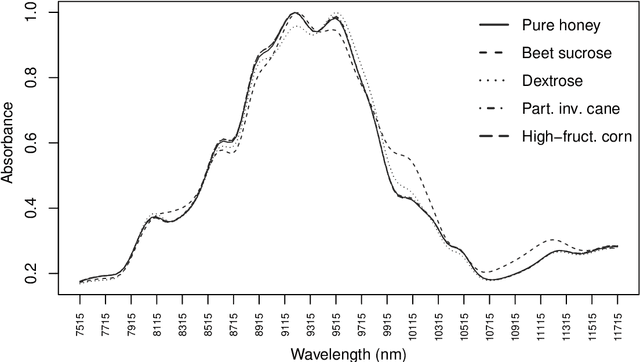
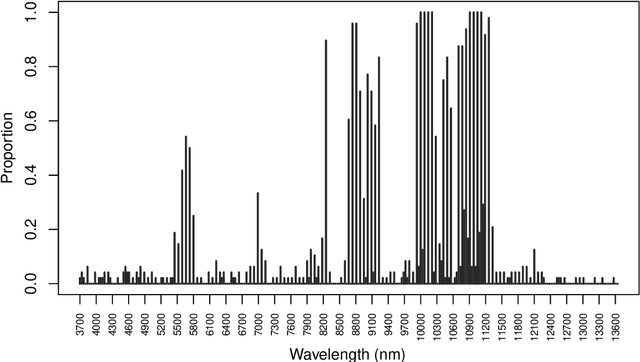
In supervised classification problems, the test set may contain data points belonging to classes not observed in the learning phase. Moreover, the same units in the test data may be measured on a set of additional variables recorded at a subsequent stage with respect to when the learning sample was collected. In this situation, the classifier built in the learning phase needs to adapt to handle potential unknown classes and the extra dimensions. We introduce a model-based discriminant approach, Dimension-Adaptive Mixture Discriminant Analysis (D-AMDA), which can detect unobserved classes and adapt to the increasing dimensionality. Model estimation is carried out via a full inductive approach based on an EM algorithm. The method is then embedded in a more general framework for adaptive variable selection and classification suitable for data of large dimensions. A simulation study and an artificial experiment related to classification of adulterated honey samples are used to validate the ability of the proposed framework to deal with complex situations.
Variable Selection Methods for Model-based Clustering
Jun 04, 2018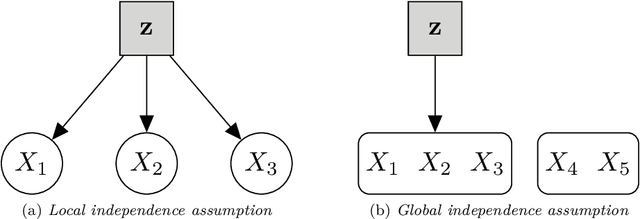
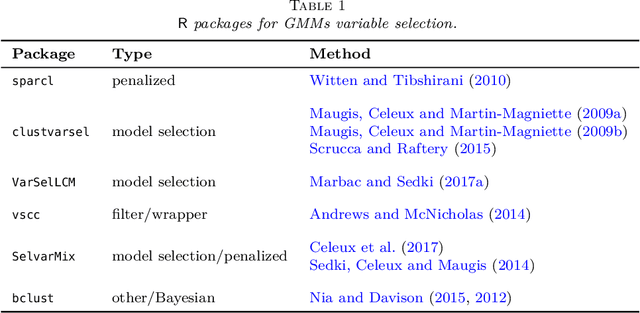
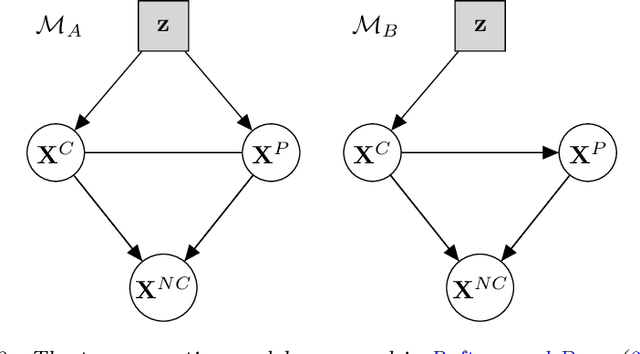
Model-based clustering is a popular approach for clustering multivariate data which has seen applications in numerous fields. Nowadays, high-dimensional data are more and more common and the model-based clustering approach has adapted to deal with the increasing dimensionality. In particular, the development of variable selection techniques has received a lot of attention and research effort in recent years. Even for small size problems, variable selection has been advocated to facilitate the interpretation of the clustering results. This review provides a summary of the methods developed for variable selection in model-based clustering. Existing R packages implementing the different methods are indicated and illustrated in application to two data analysis examples.