 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deep Latent Position Topic Model for Clustering and Representation of Networks with Textual Edges
Apr 14, 2023Numerical interactions leading to users sharing textual content published by others are naturally represented by a network where the individuals are associated with the nodes and the exchanged texts with the edges. To understand those heterogeneous and complex data structures, clustering nodes into homogeneous groups as well as rendering a comprehensible visualisation of the data is mandatory. To address both issues, we introduce Deep-LPTM, a model-based clustering strategy relying on a variational graph auto-encoder approach as well as a probabilistic model to characterise the topics of discussion. Deep-LPTM allows to build a joint representation of the nodes and of the edges in two embeddings spaces. The parameters are inferred using a variational inference algorithm. We also introduce IC2L, a model selection criterion specifically designed to choose models with relevant clustering and visualisation properties. An extensive benchmark study on synthetic data is provided. In particular, we find that Deep-LPTM better recovers the partitions of the nodes than the state-of-the art ETSBM and STBM. Eventually, the emails of the Enron company are analysed and visualisations of the results are presented, with meaningful highlights of the graph structure.
Cluster-Specific Predictions with Multi-Task Gaussian Processes
Nov 17, 2020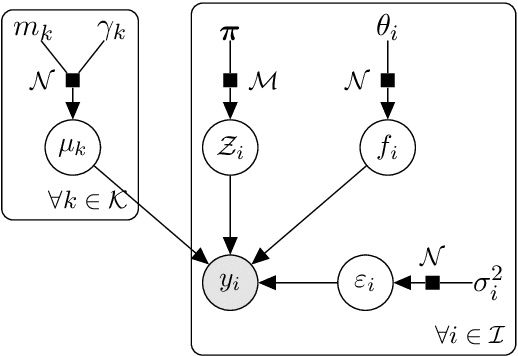


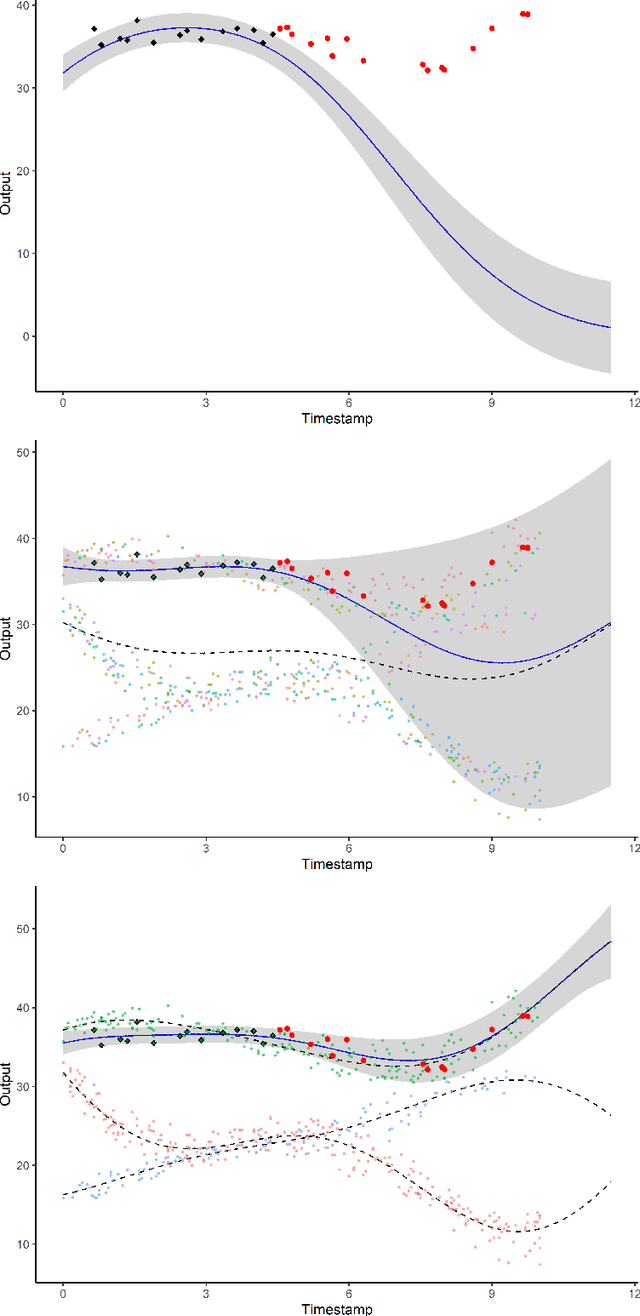
A model involving Gaussian processes (GPs) is introduced to simultaneously handle multi-task learning, clustering, and prediction for multiple functional data. This procedure acts as a model-based clustering method for functional data as well as a learning step for subsequent predictions for new tasks. The model is instantiated as a mixture of multi-task GPs with common mean processes. A variational EM algorithm is derived for dealing with the optimisation of the hyper-parameters along with the hyper-posteriors' estimation of latent variables and processes. We establish explicit formulas for integrating the mean processes and the latent clustering variables within a predictive distribution, accounting for uncertainty on both aspects. This distribution is defined as a mixture of cluster-specific GP predictions, which enhances the performances when dealing with group-structured data. The model handles irregular grid of observations and offers different hypotheses on the covariance structure for sharing additional information across tasks. The performances on both clustering and prediction tasks are assessed through various simulated scenarios and real datasets. The overall algorithm, called MagmaClust, is publicly available as an R package.
MAGMA: Inference and Prediction with Multi-Task Gaussian Processes
Jul 21, 2020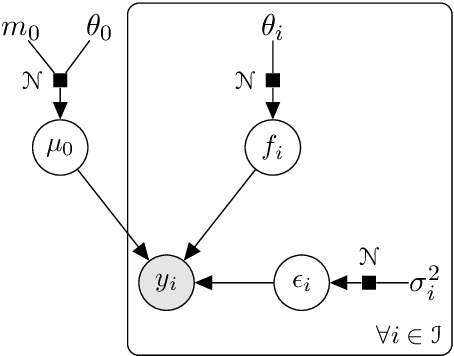
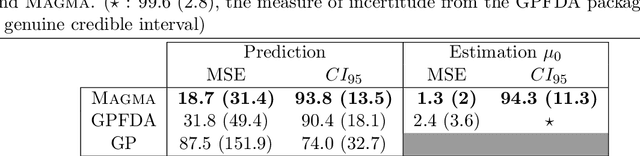
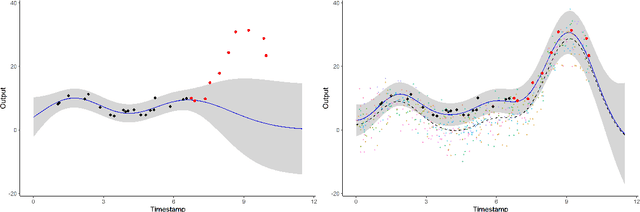
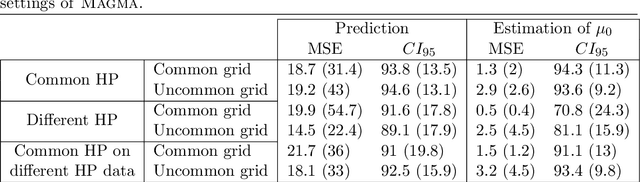
We investigate the problem of multiple time series forecasting, with the objective to improve multiple-step-ahead predictions. We propose a multi-task Gaussian process framework to simultaneously model batches of individuals with a common mean function and a specific covariance structure. This common mean is defined as a Gaussian process for which the hyper-posterior distribution is tractable. Therefore an EM algorithm can be derived for simultaneous hyper-parameters optimisation and hyper-posterior computation. Unlike previous approaches in the literature, we account for uncertainty and handle uncommon grids of observations while maintaining explicit formulations, by modelling the mean process in a non-parametric probabilistic framework. We also provide predictive formulas integrating this common mean process. This approach greatly improves the predictive performance far from observations, where information shared across individuals provides a relevant prior mean. Our overall algorithm is called \textsc{Magma} (standing for Multi tAsk Gaussian processes with common MeAn), and publicly available as a R package. The quality of the mean process estimation, predictive performances, and comparisons to alternatives are assessed in various simulated scenarios and on real datasets.
Block modelling in dynamic networks with non-homogeneous Poisson processes and exact ICL
Jul 10, 2017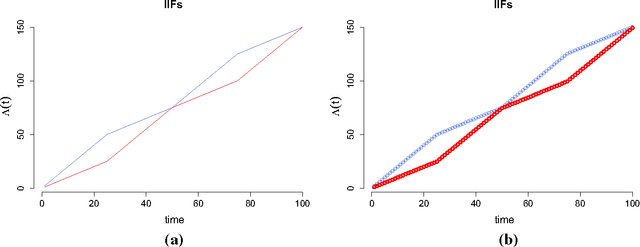
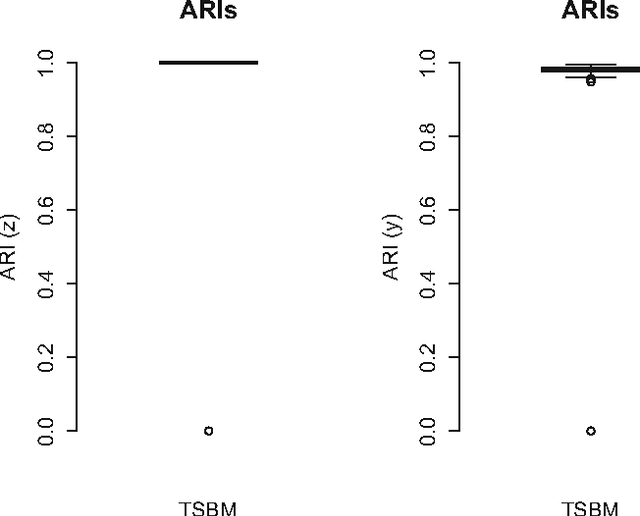
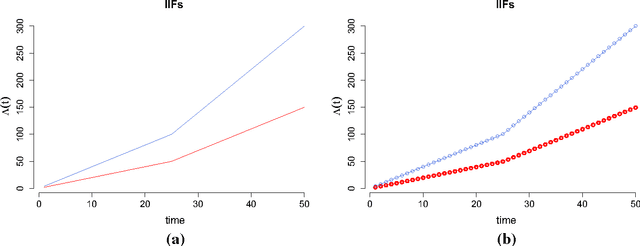
We develop a model in which interactions between nodes of a dynamic network are counted by non homogeneous Poisson processes. In a block modelling perspective, nodes belong to hidden clusters (whose number is unknown) and the intensity functions of the counting processes only depend on the clusters of nodes. In order to make inference tractable we move to discrete time by partitioning the entire time horizon in which interactions are observed in fixed-length time sub-intervals. First, we derive an exact integrated classification likelihood criterion and maximize it relying on a greedy search approach. This allows to estimate the memberships to clusters and the number of clusters simultaneously. Then a maximum-likelihood estimator is developed to estimate non parametrically the integrated intensities. We discuss the over-fitting problems of the model and propose a regularized version solving these issues. Experiments on real and simulated data are carried out in order to assess the proposed methodology.
Exact ICL maximization in a non-stationary temporal extension of the stochastic block model for dynamic networks
Jul 10, 2017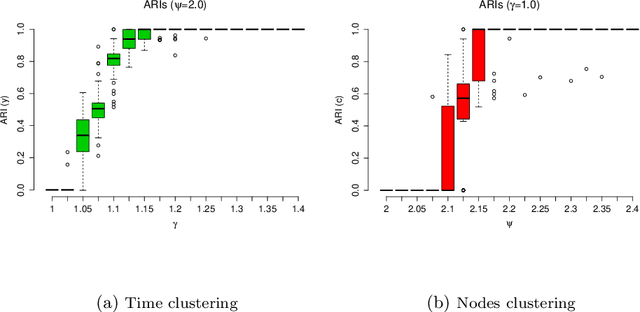
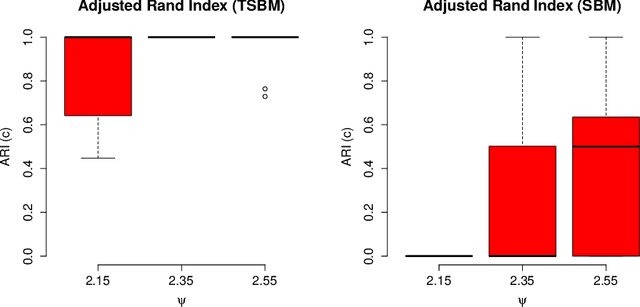
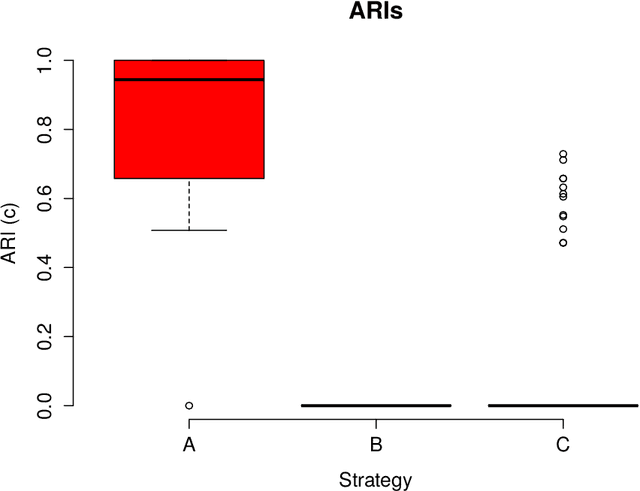
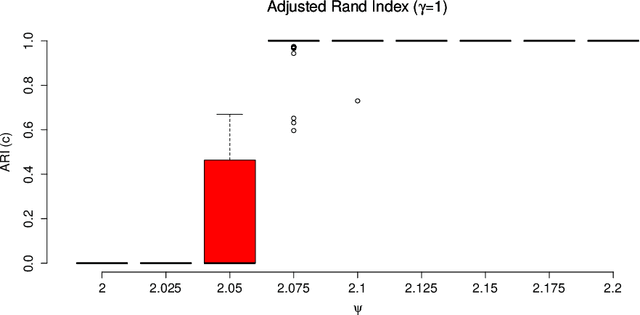
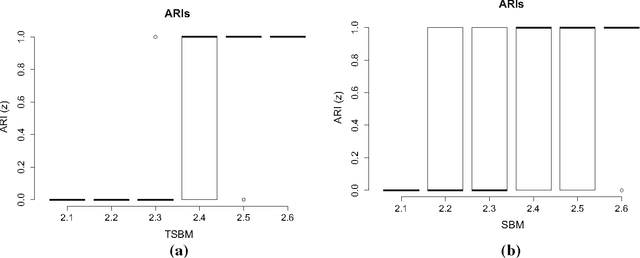
The stochastic block model (SBM) is a flexible probabilistic tool that can be used to model interactions between clusters of nodes in a network. However, it does not account for interactions of time varying intensity between clusters. The extension of the SBM developed in this paper addresses this shortcoming through a temporal partition: assuming interactions between nodes are recorded on fixed-length time intervals, the inference procedure associated with the model we propose allows to cluster simultaneously the nodes of the network and the time intervals. The number of clusters of nodes and of time intervals, as well as the memberships to clusters, are obtained by maximizing an exact integrated complete-data likelihood, relying on a greedy search approach. Experiments on simulated and real data are carried out in order to assess the proposed methodology.
Exact Dimensionality Selection for Bayesian PCA
Mar 08, 2017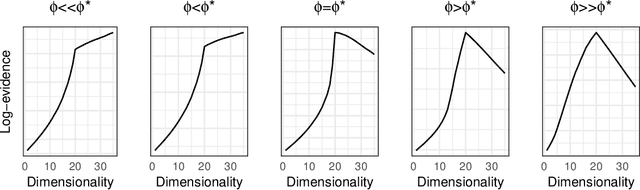
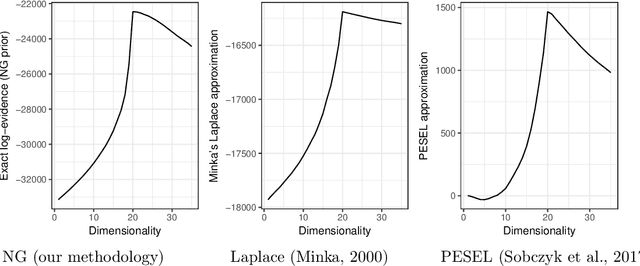

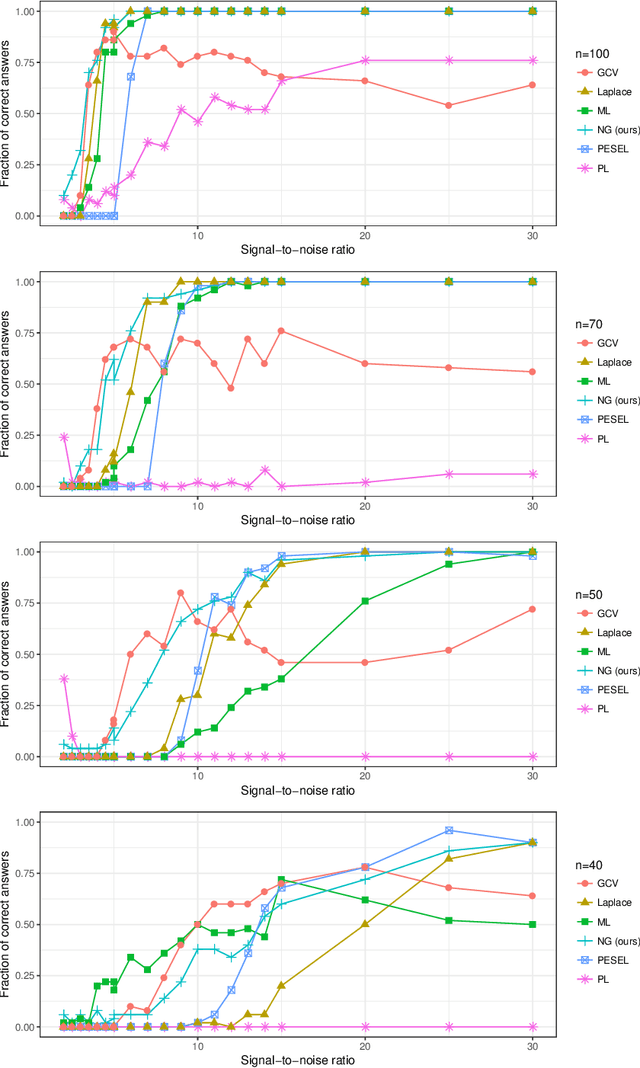
We present a Bayesian model selection approach to estimate the intrinsic dimensionality of a high-dimensional dataset. To this end, we introduce a novel formulation of the probabilisitic principal component analysis model based on a normal-gamma prior distribution. In this context, we exhibit a closed-form expression of the marginal likelihood which allows to infer an optimal number of components. We also propose a heuristic based on the expected shape of the marginal likelihood curve in order to choose the hyperparameters. In non-asymptotic frameworks, we show on simulated data that this exact dimensionality selection approach is competitive with both Bayesian and frequentist state-of-the-art methods.
Bayesian Variable Selection for Globally Sparse Probabilistic PCA
Sep 20, 2016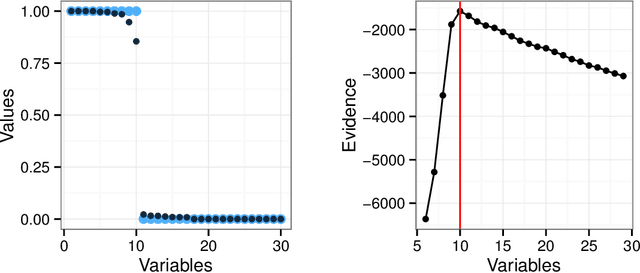

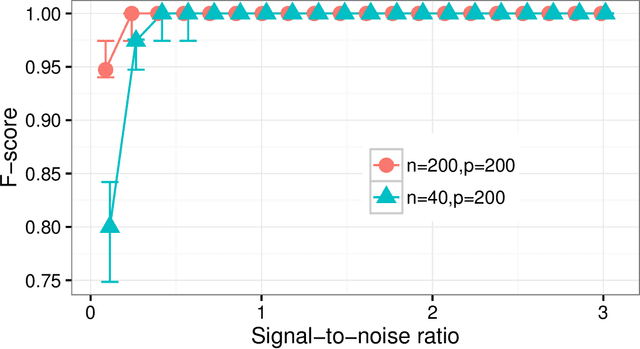

Sparse versions of principal component analysis (PCA) have imposed themselves as simple, yet powerful ways of selecting relevant features of high-dimensional data in an unsupervised manner. However, when several sparse principal components are computed, the interpretation of the selected variables is difficult since each axis has its own sparsity pattern and has to be interpreted separately. To overcome this drawback, we propose a Bayesian procedure called globally sparse probabilistic PCA (GSPPCA) that allows to obtain several sparse components with the same sparsity pattern. This allows the practitioner to identify the original variables which are relevant to describe the data. To this end, using Roweis' probabilistic interpretation of PCA and a Gaussian prior on the loading matrix, we provide the first exact computation of the marginal likelihood of a Bayesian PCA model. To avoid the drawbacks of discrete model selection, a simple relaxation of this framework is presented. It allows to find a path of models using a variational expectation-maximization algorithm. The exact marginal likelihood is then maximized over this path. This approach is illustrated on real and synthetic data sets. In particular, using unlabeled microarray data, GSPPCA infers much more relevant gene subsets than traditional sparse PCA algorithms.
Modelling time evolving interactions in networks through a non stationary extension of stochastic block models
Sep 08, 2015
In this paper, we focus on the stochastic block model (SBM),a probabilistic tool describing interactions between nodes of a network using latent clusters. The SBM assumes that the networkhas a stationary structure, in which connections of time varying intensity are not taken into account. In other words, interactions between two groups are forced to have the same features during the whole observation time. To overcome this limitation,we propose a partition of the whole time horizon, in which interactions are observed, and develop a non stationary extension of the SBM,allowing to simultaneously cluster the nodes in a network along with fixed time intervals in which the interactions take place. The number of clusters (K for nodes, D for time intervals) as well as the class memberships are finallyobtained through maximizing the complete-data integrated likelihood by means of a greedy search approach. After showing that the model works properly with simulated data, we focus on a real data set. We thus consider the three days ACM Hypertext conference held in Turin,June 29th - July 1st 2009. Proximity interactions between attendees during the first day are modelled and an interestingclustering of the daily hours is finally obtained, with times of social gathering (e.g. coffee breaks) recovered by the approach. Applications to large networks are limited due to the computational complexity of the greedy search which is dominated bythe number $K\_{max}$ and $D\_{max}$ of clusters used in the initialization. Therefore,advanced clustering tools are considered to reduce the number of clusters expected in the data, making the greedy search applicable to large networks.
Graphs in machine learning: an introduction
Jun 23, 2015Graphs are commonly used to characterise interactions between objects of interest. Because they are based on a straightforward formalism, they are used in many scientific fields from computer science to historical sciences. In this paper, we give an introduction to some methods relying on graphs for learning. This includes both unsupervised and supervised methods. Unsupervised learning algorithms usually aim at visualising graphs in latent spaces and/or clustering the nodes. Both focus on extracting knowledge from graph topologies. While most existing techniques are only applicable to static graphs, where edges do not evolve through time, recent developments have shown that they could be extended to deal with evolving networks. In a supervised context, one generally aims at inferring labels or numerical values attached to nodes using both the graph and, when they are available, node characteristics. Balancing the two sources of information can be challenging, especially as they can disagree locally or globally. In both contexts, supervised and un-supervised, data can be relational (augmented with one or several global graphs) as described above, or graph valued. In this latter case, each object of interest is given as a full graph (possibly completed by other characteristics). In this context, natural tasks include graph clustering (as in producing clusters of graphs rather than clusters of nodes in a single graph), graph classification, etc. 1 Real networks One of the first practical studies on graphs can be dated back to the original work of Moreno [51] in the 30s. Since then, there has been a growing interest in graph analysis associated with strong developments in the modelling and the processing of these data. Graphs are now used in many scientific fields. In Biology [54, 2, 7], for instance, metabolic networks can describe pathways of biochemical reactions [41], while in social sciences networks are used to represent relation ties between actors [66, 56, 36, 34]. Other examples include powergrids [71] and the web [75]. Recently, networks have also been considered in other areas such as geography [22] and history [59, 39]. In machine learning, networks are seen as powerful tools to model problems in order to extract information from data and for prediction purposes. This is the object of this paper. For more complete surveys, we refer to [28, 62, 49, 45]. In this section, we introduce notations and highlight properties shared by most real networks. In Section 2, we then consider methods aiming at extracting information from a unique network. We will particularly focus on clustering methods where the goal is to find clusters of vertices. Finally, in Section 3, techniques that take a series of networks into account, where each network is
Exact ICL maximization in a non-stationary time extension of the latent block model for dynamic networks
Jun 12, 2015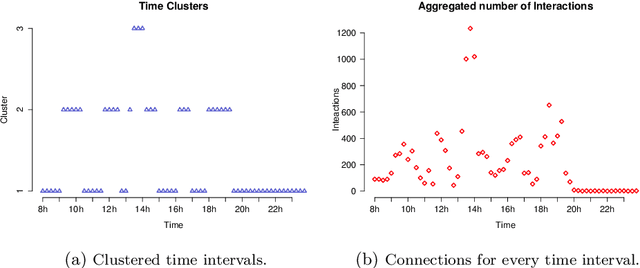
The latent block model (LBM) is a flexible probabilistic tool to describe interactions between node sets in bipartite networks, but it does not account for interactions of time varying intensity between nodes in unknown classes. In this paper we propose a non stationary temporal extension of the LBM that clusters simultaneously the two node sets of a bipartite network and constructs classes of time intervals on which interactions are stationary. The number of clusters as well as the membership to classes are obtained by maximizing the exact complete-data integrated likelihood relying on a greedy search approach. Experiments on simulated and real data are carried out in order to assess the proposed methodology.