 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCC: A Cascade based Approach to Detect Communities in Social Networks
Dec 21, 2022



Community detection in Social Networks is associated with finding and grouping the most similar nodes inherent in the network. These similar nodes are identified by computing tie strength. Stronger ties indicates higher proximity shared by connected node pairs. This work is motivated by Granovetter's argument that suggests that strong ties lies within densely connected nodes and the theory that community cores in real-world networks are densely connected. In this paper, we have introduced a novel method called \emph{Disjoint Community detection using Cascades (DCC)} which demonstrates the effectiveness of a new local density based tie strength measure on detecting communities. Here, tie strength is utilized to decide the paths followed for propagating information. The idea is to crawl through the tuple information of cascades towards the community core guided by increasing tie strength. Considering the cascade generation step, a novel preferential membership method has been developed to assign community labels to unassigned nodes. The efficacy of $DCC$ has been analyzed based on quality and accuracy on several real-world datasets and baseline community detection algorithms.
Direct Comparative Analysis of Nature-inspired Optimization Algorithms on Community Detection Problem in Social Networks
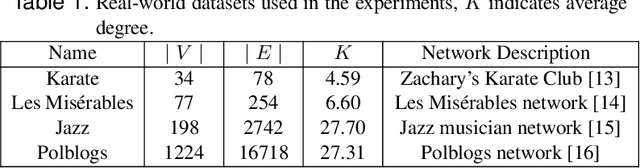
Dec 21, 2022Nature-inspired optimization Algorithms (NIOAs) are nowadays a popular choice for community detection in social networks. Community detection problem in social network is treated as optimization problem, where the objective is to either maximize the connection within the community or minimize connections between the communities. To apply NIOAs, either of the two, or both objectives are explored. Since NIOAs mostly exploit randomness in their strategies, it is necessary to analyze their performance for specific applications. In this paper, NIOAs are analyzed on the community detection problem. A direct comparison approach is followed to perform pairwise comparison of NIOAs. The performance is measured in terms of five scores designed based on prasatul matrix and also with average isolability. Three widely used real-world social networks and four NIOAs are considered for analyzing the quality of communities generated by NIOAs.
Beyond Information Exchange: An Approach to Deploy Network Properties for Information Diffusion
Dec 21, 2022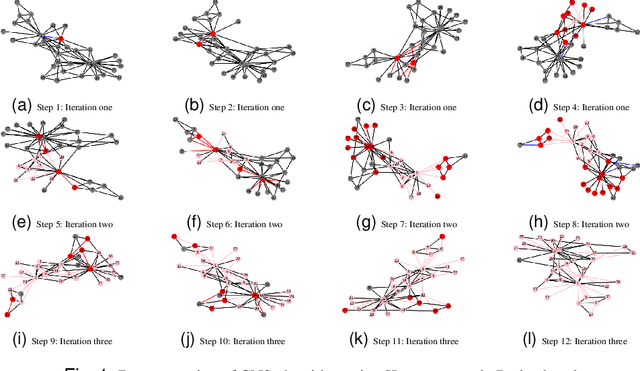


Information diffusion in Online Social Networks is a new and crucial problem in social network analysis field and requires significant research attention. Efficient diffusion of information are of critical importance in diverse situations such as; pandemic prevention, advertising, marketing etc. Although several mathematical models have been developed till date, but previous works lacked systematic analysis and exploration of the influence of neighborhood for information diffusion. In this paper, we have proposed Common Neighborhood Strategy (CNS) algorithm for information diffusion that demonstrates the role of common neighborhood in information propagation throughout the network. The performance of CNS algorithm is evaluated on several real-world datasets in terms of diffusion speed and diffusion outspread and compared with several widely used information diffusion models. Empirical results show CNS algorithm enables better information diffusion both in terms of diffusion speed and diffusion outspread.
The Ties that matter: From the perspective of Similarity Measure in Online Social Networks
Dec 21, 2022Online Social Networks have embarked on the importance of connection strength measures which has a broad array of applications such as, analyzing diffusion behaviors, community detection, link predictions, recommender systems. Though there are some existing connection strength measures, the density that a connection shares with it's neighbors and the directionality aspect has not received much attention. In this paper, we have proposed an asymmetric edge similarity measure namely, Neighborhood Density-based Edge Similarity (NDES) which provides a fundamental support to derive the strength of connection. The time complexity of NDES is $O(nk^2)$. An application of NDES for community detection in social network is shown. We have considered a similarity based community detection technique and substituted its similarity measure with NDES. The performance of NDES is evaluated on several small real-world datasets in terms of the effectiveness in detecting communities and compared with three widely used similarity measures. Empirical results show NDES enables detecting comparatively better communities both in terms of accuracy and quality.
Prasatul Matrix: A Direct Comparison Approach for Analyzing Evolutionary Optimization Algorithms
Dec 01, 2022The performance of individual evolutionary optimization algorithms is mostly measured in terms of statistics such as mean, median and standard deviation etc., computed over the best solutions obtained with few trails of the algorithm. To compare the performance of two algorithms, the values of these statistics are compared instead of comparing the solutions directly. This kind of comparison lacks direct comparison of solutions obtained with different algorithms. For instance, the comparison of best solutions (or worst solution) of two algorithms simply not possible. Moreover, ranking of algorithms is mostly done in terms of solution quality only, despite the fact that the convergence of algorithm is also an important factor. In this paper, a direct comparison approach is proposed to analyze the performance of evolutionary optimization algorithms. A direct comparison matrix called \emph{Prasatul Matrix} is prepared, which accounts direct comparison outcome of best solutions obtained with two algorithms for a specific number of trials. Five different performance measures are designed based on the prasatul matrix to evaluate the performance of algorithms in terms of Optimality and Comparability of solutions. These scores are utilized to develop a score-driven approach for comparing performance of multiple algorithms as well as for ranking both in the grounds of solution quality and convergence analysis. Proposed approach is analyzed with six evolutionary optimization algorithms on 25 benchmark functions. A non-parametric statistical analysis, namely Wilcoxon paired sum-rank test is also performed to verify the outcomes of proposed direct comparison approach.
Introductory Review of Swarm Intelligence Techniques
Sep 30, 2022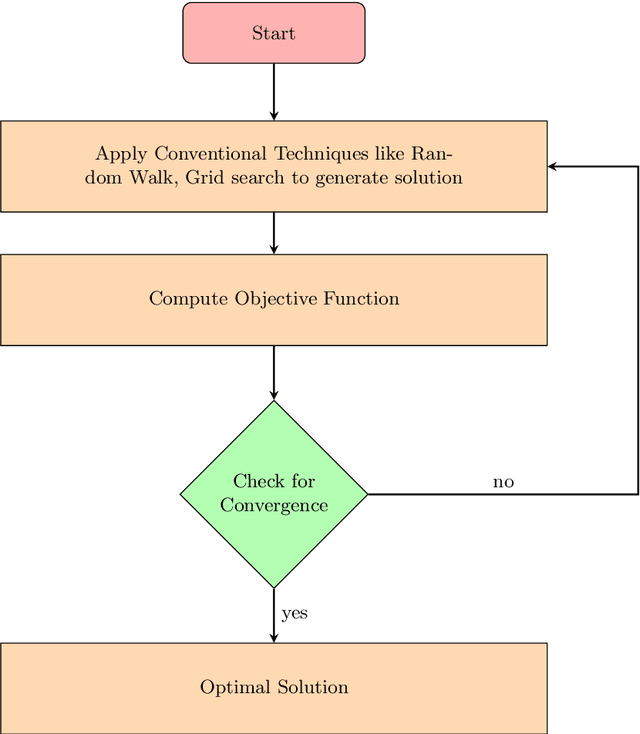
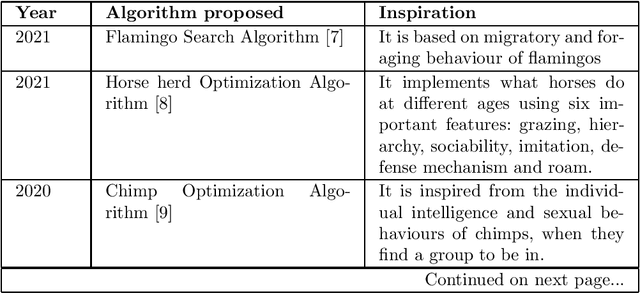
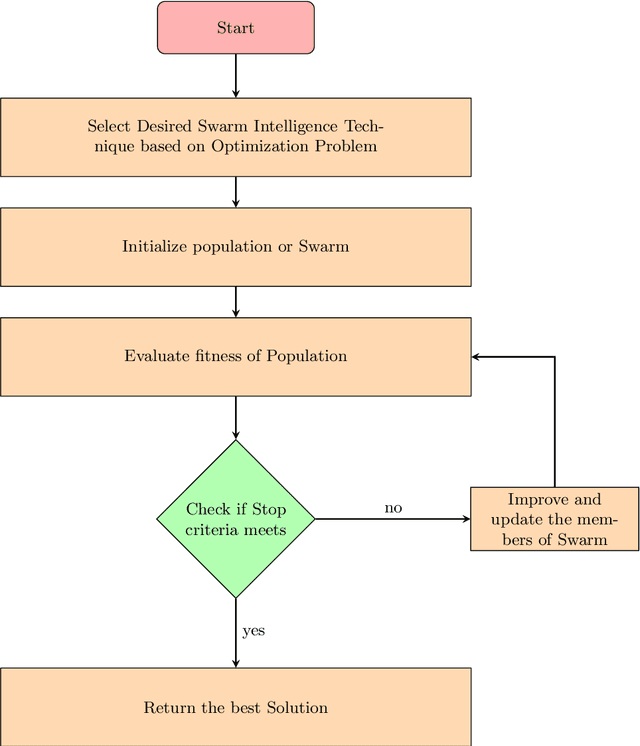
With the rapid upliftment of technology, there has emerged a dire need to fine-tune or optimize certain processes, software, models or structures, with utmost accuracy and efficiency. Optimization algorithms are preferred over other methods of optimization through experimentation or simulation, for their generic problem-solving abilities and promising efficacy with the least human intervention. In recent times, the inducement of natural phenomena into algorithm design has immensely triggered the efficiency of optimization process for even complex multi-dimensional, non-continuous, non-differentiable and noisy problem search spaces. This chapter deals with the Swarm intelligence (SI) based algorithms or Swarm Optimization Algorithms, which are a subset of the greater Nature Inspired Optimization Algorithms (NIOAs). Swarm intelligence involves the collective study of individuals and their mutual interactions leading to intelligent behavior of the swarm. The chapter presents various population-based SI algorithms, their fundamental structures along with their mathematical models.
Artificial Intelligence for Cybersecurity: Threats, Attacks and Mitigation
Sep 27, 2022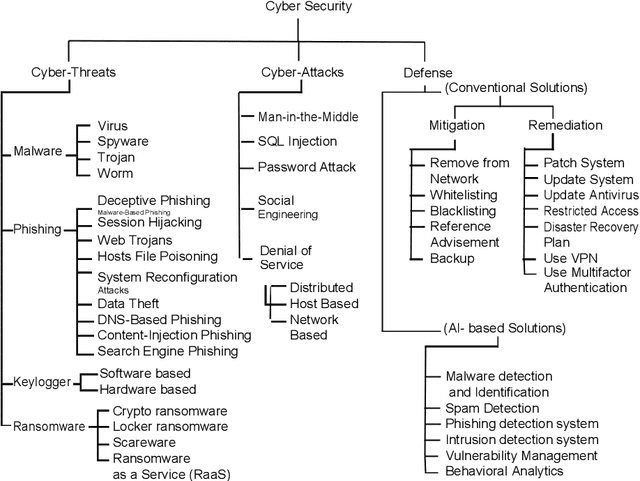
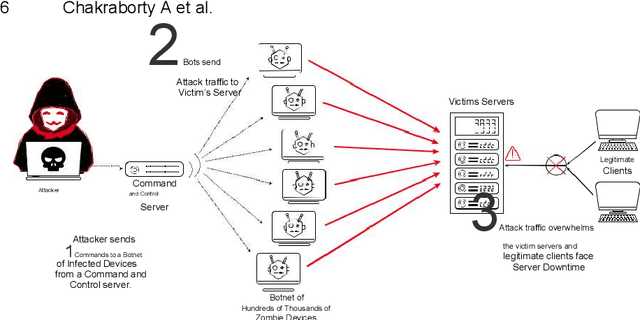
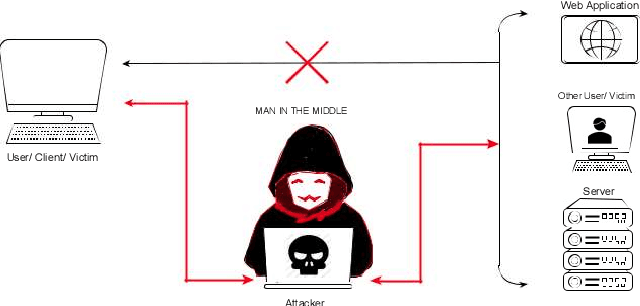
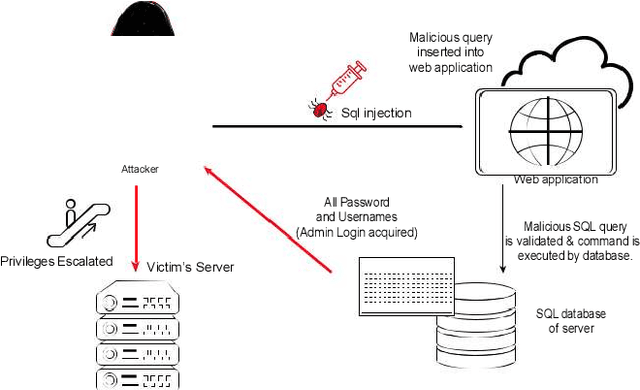
With the advent of the digital era, every day-to-day task is automated due to technological advances. However, technology has yet to provide people with enough tools and safeguards. As the internet connects more-and-more devices around the globe, the question of securing the connected devices grows at an even spiral rate. Data thefts, identity thefts, fraudulent transactions, password compromises, and system breaches are becoming regular everyday news. The surging menace of cyber-attacks got a jolt from the recent advancements in Artificial Intelligence. AI is being applied in almost every field of different sciences and engineering. The intervention of AI not only automates a particular task but also improves efficiency by many folds. So it is evident that such a scrumptious spread would be very appetizing to cybercriminals. Thus the conventional cyber threats and attacks are now ``intelligent" threats. This article discusses cybersecurity and cyber threats along with both conventional and intelligent ways of defense against cyber-attacks. Furthermore finally, end the discussion with the potential prospects of the future of AI in cybersecurity.
Design Perspectives of Multitask Deep Learning Models and Applications
Sep 27, 2022In recent years, multi-task learning has turned out to be of great success in various applications. Though single model training has promised great results throughout these years, it ignores valuable information that might help us estimate a metric better. Under learning-related tasks, multi-task learning has been able to generalize the models even better. We try to enhance the feature mapping of the multi-tasking models by sharing features among related tasks and inductive transfer learning. Also, our interest is in learning the task relationships among various tasks for acquiring better benefits from multi-task learning. In this chapter, our objective is to visualize the existing multi-tasking models, compare their performances, the methods used to evaluate the performance of the multi-tasking models, discuss the problems faced during the design and implementation of these models in various domains, and the advantages and milestones achieved by them
Towards Direct Comparison of Community Structures in Social Networks
Sep 26, 2022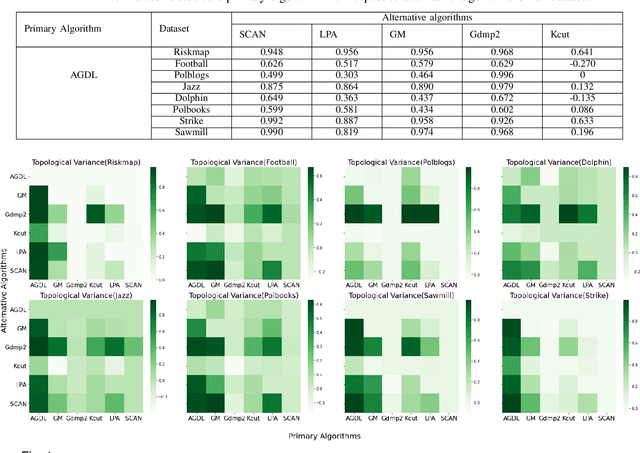
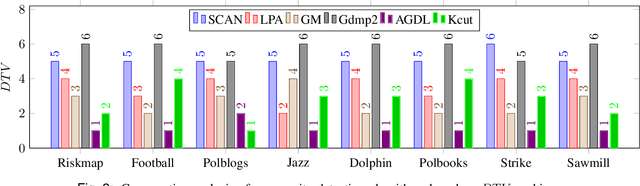
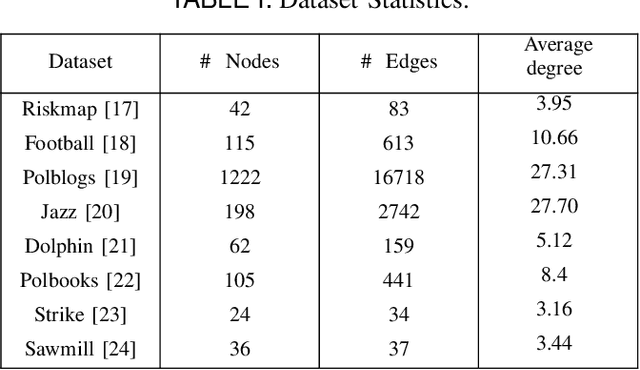

Community detection algorithms are in general evaluated by comparing evaluation metric values for the communities obtained with different algorithms. The evaluation metrics that are used for measuring quality of the communities incorporate the topological information of entities like connectivity of the nodes within or outside the communities. However, while comparing the metric values it loses direct involvement of topological information of the communities in the comparison process. In this paper, a direct comparison approach is proposed where topological information of the communities obtained with two algorithms are compared directly. A quality measure namely \emph{Topological Variance (TV)} is designed based on direct comparison of topological information of the communities. Considering the newly designed quality measure, two ranking schemes are developed. The efficacy of proposed quality metric as well as the ranking scheme is studied with eight widely used real-world datasets and six community detection algorithms.
Prayatul Matrix: A Direct Comparison Approach to Evaluate Performance of Supervised Machine Learning Models
Sep 26, 2022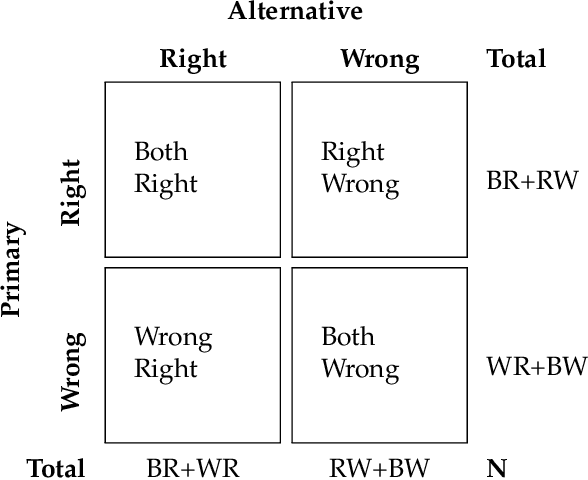

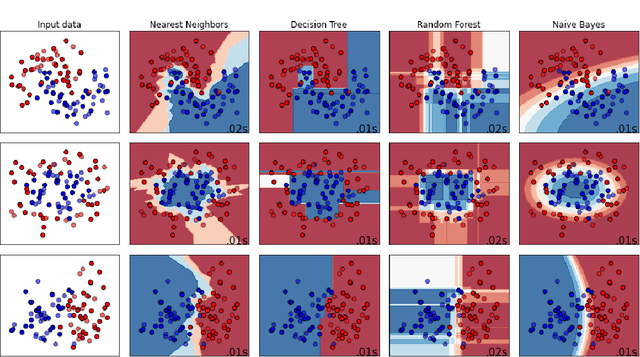

Performance comparison of supervised machine learning (ML) models are widely done in terms of different confusion matrix based scores obtained on test datasets. However, a dataset comprises several instances having different difficulty levels. Therefore, it is more logical to compare effectiveness of ML models on individual instances instead of comparing scores obtained for the entire dataset. In this paper, an alternative approach is proposed for direct comparison of supervised ML models in terms of individual instances within the dataset. A direct comparison matrix called \emph{Prayatul Matrix} is introduced, which accounts for comparative outcome of two ML algorithms on different instances of a dataset. Five different performance measures are designed based on prayatul matrix. Efficacy of the proposed approach as well as designed measures is analyzed with four classification techniques on three datasets. Also analyzed on four large-scale complex image datasets with four deep learning models namely ResNet50V2, MobileNetV2, EfficientNet, and XceptionNet. Results are evident that the newly designed measure are capable of giving more insight about the comparing ML algorithms, which were impossible with existing confusion matrix based scores like accuracy, precision and recall.