 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 Detection from Mass Spectra of Exhaled Breath
May 30, 2023According to the World Health Organization, the SARS-CoV-2 virus generated a global emergency between 2020 and 2023 resulting in about 7 million deaths out of more than 750 million individuals diagnosed with COVID-19. During these years, polymerase-chain-reaction and antigen testing played a prominent role in disease control. In this study, we propose a fast and non-invasive detection system exploiting a proprietary mass spectrometer to measure ions in exhaled breath. We demonstrated that infected individuals, even if asymptomatic, exhibit characteristics in the air expelled from the lungs that can be detected by a nanotech-based technology and then recognized by soft-computing algorithms. A clinical trial was ran on about 300 patients: the mass spectra in the 10-351 mass-to-charge range were measured, suitably pre-processed, and analyzed by different classification models; eventually, the system shown an accuracy of 95% and a recall of 94% in identifying cases of COVID-19. With performances comparable to traditional methodologies, the proposed system could play a significant role in both routine examination for common diseases and emergency response for new epidemics.
Modeling Generalization in Machine Learning: A Methodological and Computational Study
Jun 28, 2020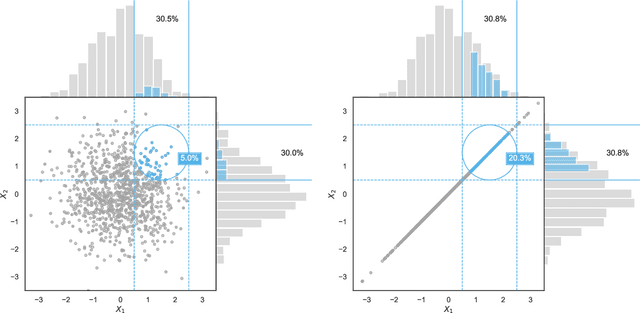
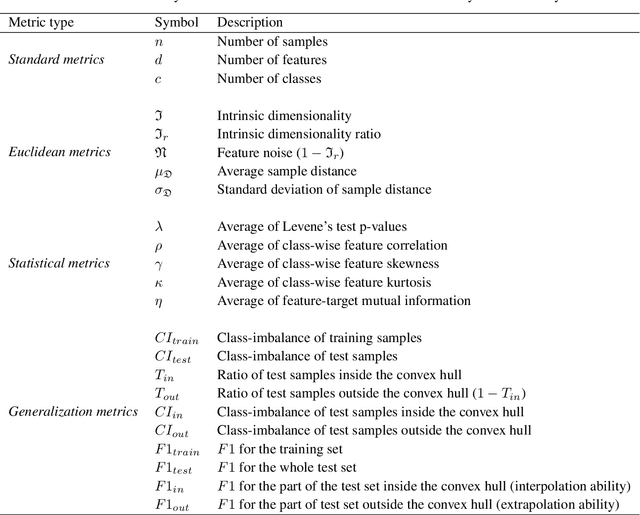
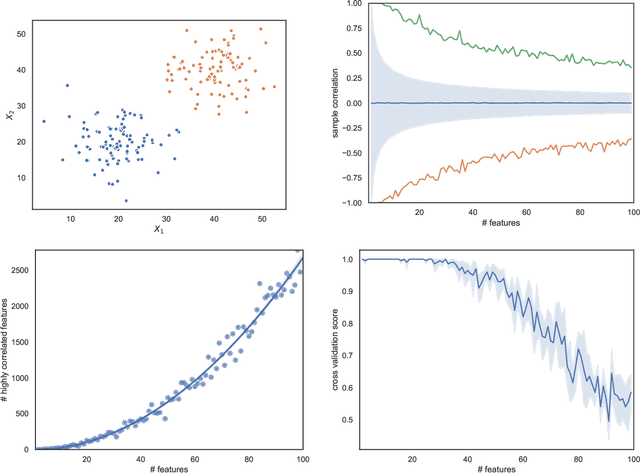
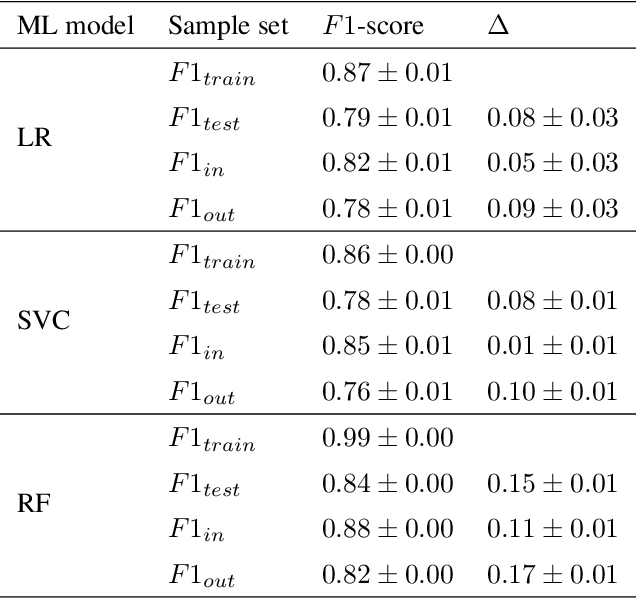
As machine learning becomes more and more available to the general public, theoretical questions are turning into pressing practical issues. Possibly, one of the most relevant concerns is the assessment of our confidence in trusting machine learning predictions. In many real-world cases, it is of utmost importance to estimate the capabilities of a machine learning algorithm to generalize, i.e., to provide accurate predictions on unseen data, depending on the characteristics of the target problem. In this work, we perform a meta-analysis of 109 publicly-available classification data sets, modeling machine learning generalization as a function of a variety of data set characteristics, ranging from number of samples to intrinsic dimensionality, from class-wise feature skewness to $F1$ evaluated on test samples falling outside the convex hull of the training set. Experimental results demonstrate the relevance of using the concept of the convex hull of the training data in assessing machine learning generalization, by emphasizing the difference between interpolated and extrapolated predictions. Besides several predictable correlations, we observe unexpectedly weak associations between the generalization ability of machine learning models and all metrics related to dimensionality, thus challenging the common assumption that the \textit{curse of dimensionality} might impair generalization in machine learning.
Uncovering Coresets for Classification With Multi-Objective Evolutionary Algorithms
Feb 20, 2020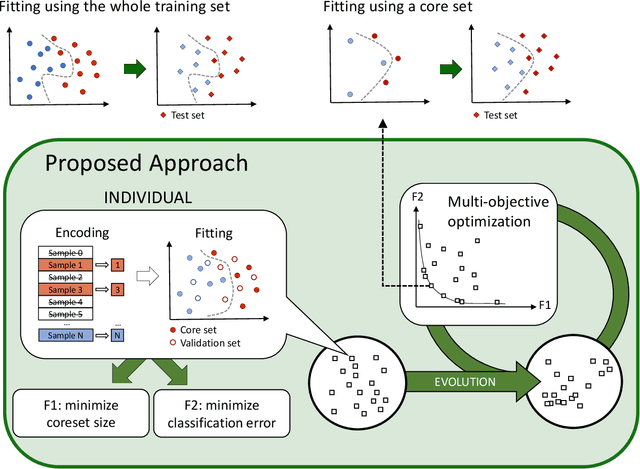
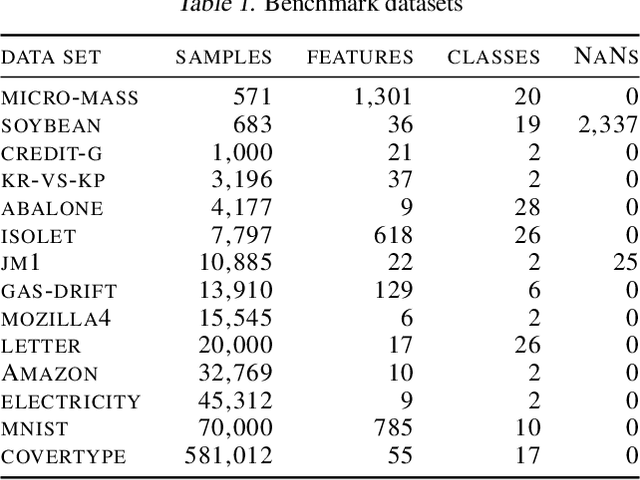
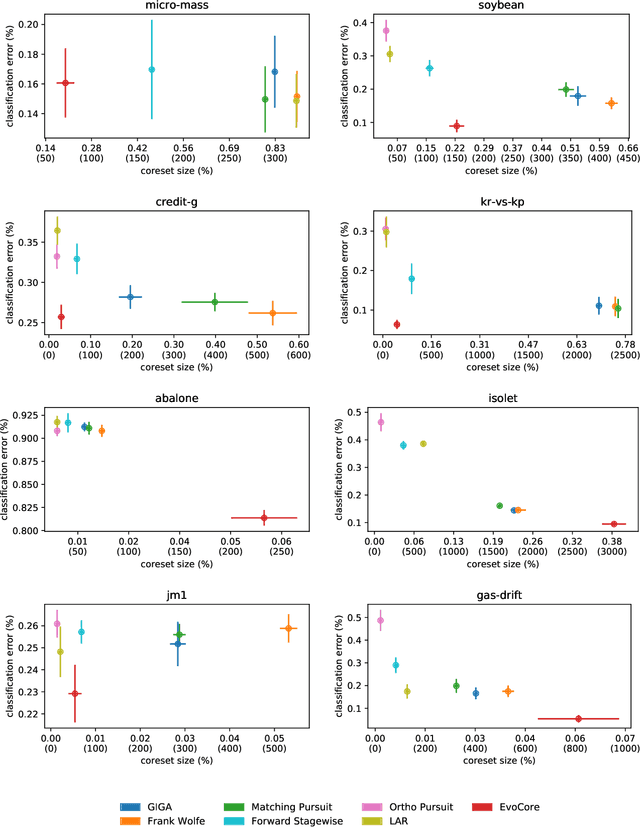
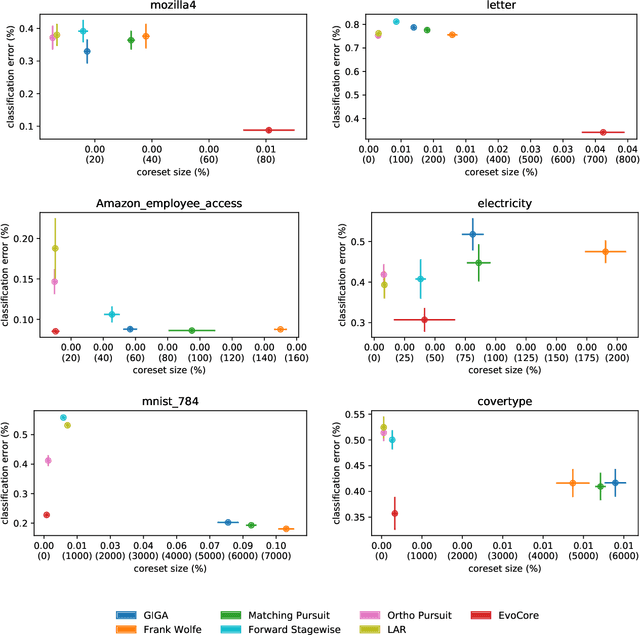
A coreset is a subset of the training set, using which a machine learning algorithm obtains performances similar to what it would deliver if trained over the whole original data. Coreset discovery is an active and open line of research as it allows improving training speed for the algorithms and may help human understanding the results. Building on previous works, a novel approach is presented: candidate corsets are iteratively optimized, adding and removing samples. As there is an obvious trade-off between limiting training size and quality of the results, a multi-objective evolutionary algorithm is used to minimize simultaneously the number of points in the set and the classification error. Experimental results on non-trivial benchmarks show that the proposed approach is able to deliver results that allow a classifier to obtain lower error and better ability of generalizing on unseen data than state-of-the-art coreset discovery techniques.