 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC3DO: Diffusion Classifier for 3D Objects
Aug 13, 2024



Inspired by Geoffrey Hinton emphasis on generative modeling, To recognize shapes, first learn to generate them, we explore the use of 3D diffusion models for object classification. Leveraging the density estimates from these models, our approach, the Diffusion Classifier for 3D Objects (DC3DO), enables zero-shot classification of 3D shapes without additional training. On average, our method achieves a 12.5 percent improvement compared to its multiview counterparts, demonstrating superior multimodal reasoning over discriminative approaches. DC3DO employs a class-conditional diffusion model trained on ShapeNet, and we run inferences on point clouds of chairs and cars. This work highlights the potential of generative models in 3D object classification.
3D-LDM: Neural Implicit 3D Shape Generation with Latent Diffusion Models
Dec 15, 2022


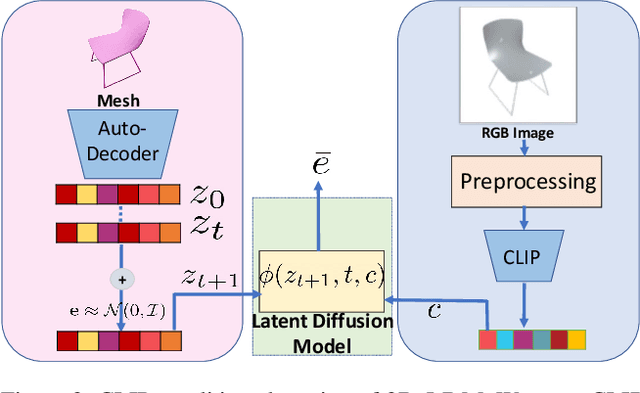
Diffusion models have shown great promise for image generation, beating GANs in terms of generation diversity, with comparable image quality. However, their application to 3D shapes has been limited to point or voxel representations that can in practice not accurately represent a 3D surface. We propose a diffusion model for neural implicit representations of 3D shapes that operates in the latent space of an auto-decoder. This allows us to generate diverse and high quality 3D surfaces. We additionally show that we can condition our model on images or text to enable image-to-3D generation and text-to-3D generation using CLIP embeddings. Furthermore, adding noise to the latent codes of existing shapes allows us to explore shape variations.