 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGemma 1.5 Technical Report
Apr 06, 2026We introduce MedGemma 1.5 4B, the latest model in the MedGemma collection. MedGemma 1.5 expands on MedGemma 1 by integrating additional capabilities: high-dimensional medical imaging (CT/MRI volumes and histopathology whole slide images), anatomical localization via bounding boxes, multi-timepoint chest X-ray analysis, and improved medical document understanding (lab reports, electronic health records). We detail the innovations required to enable these modalities within a single architecture, including new training data, long-context 3D volume slicing, and whole-slide pathology sampling. Compared to MedGemma 1 4B, MedGemma 1.5 4B demonstrates significant gains in these new areas, improving 3D MRI condition classification accuracy by 11% and 3D CT condition classification by 3% (absolute improvements). In whole slide pathology imaging, MedGemma 1.5 4B achieves a 47% macro F1 gain. Additionally, it improves anatomical localization with a 35% increase in Intersection over Union on chest X-rays and achieves a 4% macro accuracy for longitudinal (multi-timepoint) chest x-ray analysis. Beyond its improved multimodal performance over MedGemma 1, MedGemma 1.5 improves on text-based clinical knowledge and reasoning, improving by 5% on MedQA accuracy and 22% on EHRQA accuracy. It also achieves an average of 18% macro F1 on 4 different lab report information extraction datasets (EHR Datasets 2, 3, 4, and Mendeley Clinical Laboratory Test Reports). Taken together, MedGemma 1.5 serves as a robust, open resource for the community, designed as an improved foundation on which developers can create the next generation of medical AI systems. Resources and tutorials for building upon MedGemma 1.5 can be found at https://goo.gle/MedGemma.
DC3DO: Diffusion Classifier for 3D Objects
Aug 13, 2024



Inspired by Geoffrey Hinton emphasis on generative modeling, To recognize shapes, first learn to generate them, we explore the use of 3D diffusion models for object classification. Leveraging the density estimates from these models, our approach, the Diffusion Classifier for 3D Objects (DC3DO), enables zero-shot classification of 3D shapes without additional training. On average, our method achieves a 12.5 percent improvement compared to its multiview counterparts, demonstrating superior multimodal reasoning over discriminative approaches. DC3DO employs a class-conditional diffusion model trained on ShapeNet, and we run inferences on point clouds of chairs and cars. This work highlights the potential of generative models in 3D object classification.
3D-LDM: Neural Implicit 3D Shape Generation with Latent Diffusion Models
Dec 15, 2022


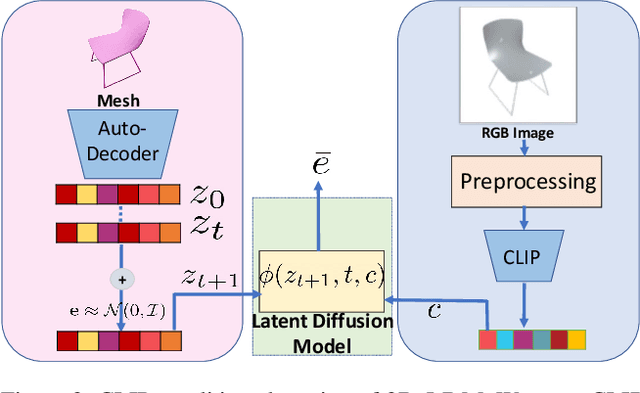
Diffusion models have shown great promise for image generation, beating GANs in terms of generation diversity, with comparable image quality. However, their application to 3D shapes has been limited to point or voxel representations that can in practice not accurately represent a 3D surface. We propose a diffusion model for neural implicit representations of 3D shapes that operates in the latent space of an auto-decoder. This allows us to generate diverse and high quality 3D surfaces. We additionally show that we can condition our model on images or text to enable image-to-3D generation and text-to-3D generation using CLIP embeddings. Furthermore, adding noise to the latent codes of existing shapes allows us to explore shape variations.
Vitruvio: 3D Building Meshes via Single Perspective Sketches
Oct 24, 2022



Today's architectural engineering and construction (AEC) software require a learning curve to generate a three-dimension building representation. This limits the ability to quickly validate the volumetric implications of an initial design idea communicated via a single sketch. Allowing designers to translate a single sketch to a 3D building will enable owners to instantly visualize 3D project information without the cognitive load required. If previous state-of-the-art (SOTA) data-driven methods for single view reconstruction (SVR) showed outstanding results in the reconstruction process from a single image or sketch, they lacked specific applications, analysis, and experiments in the AEC. Therefore, this research addresses this gap, introducing a deep learning method: Vitruvio. Vitruvio adapts Occupancy Network for SVR tasks on a specific building dataset (Manhattan 1K). This adaptation brings two main improvements. First, it accelerates the inference process by more than 26\% (from 0.5s to 0.37s). Second, it increases the reconstruction accuracy (measured by the Chamfer Distance) by 18\%. During this adaptation in the AEC domain, we evaluate the effect of the building orientation in the learning procedure since it constitutes an important design factor. While aligning all the buildings to a canonical pose improved the overall quantitative metrics, it did not capture fine-grain details in more complex building shapes (as shown in our qualitative analysis). Finally, Vitruvio outputs a 3D-printable building mesh with arbitrary topology and genus from a single perspective sketch, providing a step forward to allow owners and designers to communicate 3D information via a 2D, effective, intuitive, and universal communication medium: the sketch.
Synthetic 3D Data Generation Pipeline for Geometric Deep Learning in Architecture
Apr 26, 2021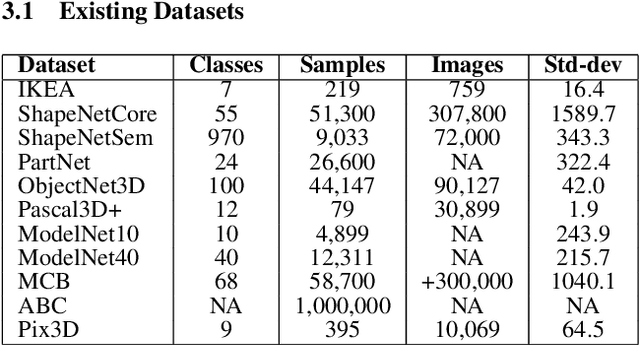
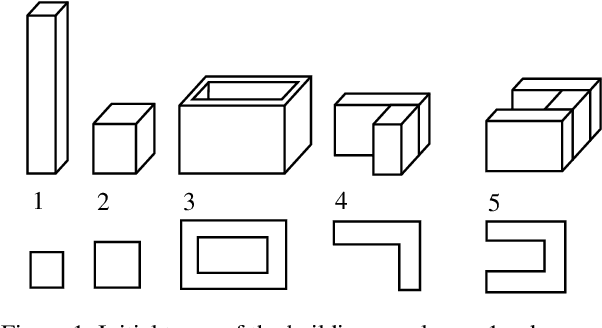
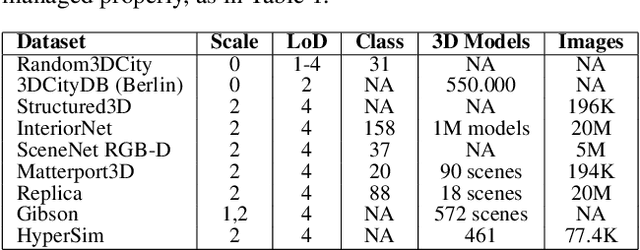
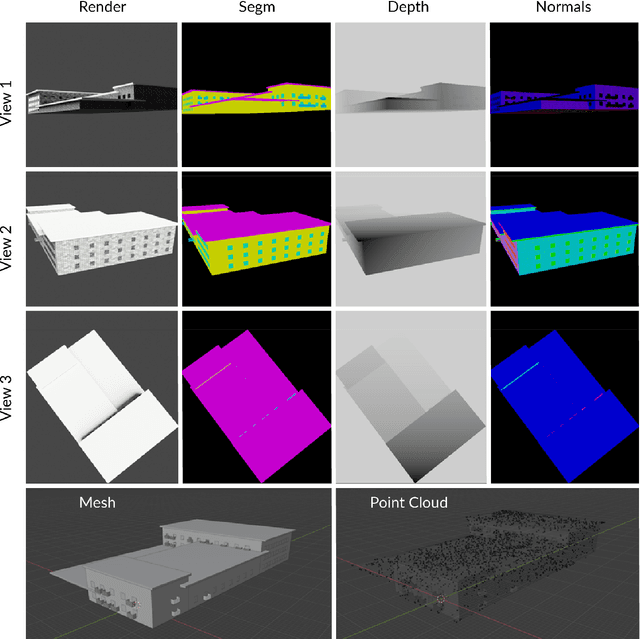
With the growing interest in deep learning algorithms and computational design in the architectural field, the need for large, accessible and diverse architectural datasets increases. We decided to tackle this problem by constructing a field-specific synthetic data generation pipeline that generates an arbitrary amount of 3D data along with the associated 2D and 3D annotations. The variety of annotations, the flexibility to customize the generated building and dataset parameters make this framework suitable for multiple deep learning tasks, including geometric deep learning that requires direct 3D supervision. Creating our building data generation pipeline we leveraged architectural knowledge from experts in order to construct a framework that would be modular, extendable and would provide a sufficient amount of class-balanced data samples. Moreover, we purposefully involve the researcher in the dataset customization allowing the introduction of additional building components, material textures, building classes, number and type of annotations as well as the number of views per 3D model sample. In this way, the framework would satisfy different research requirements and would be adaptable to a large variety of tasks. All code and data are made publicly available.