 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANs for Urban Design
May 04, 2021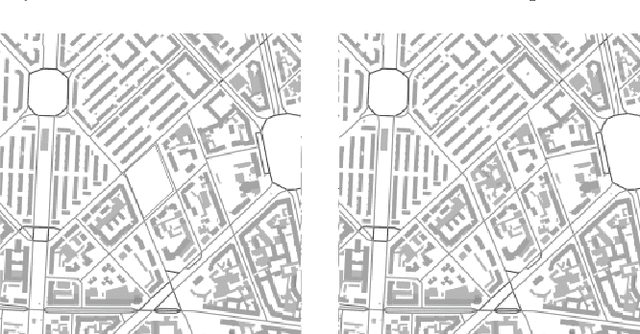

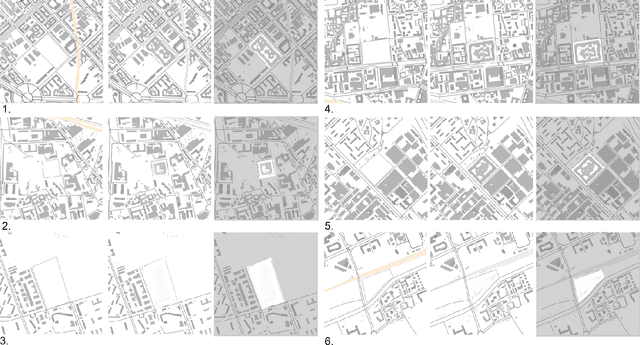
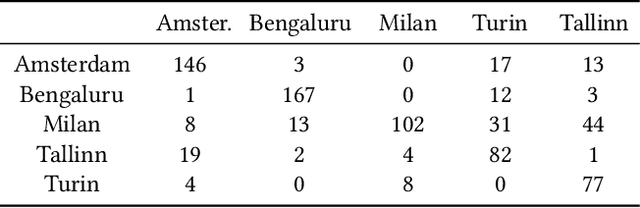
Development and diffusion of machine learning and big data tools provide a new tool for architects and urban planners that could be used as analytical or design instruments. The topic investigated in this paper is the application of Generative Adversarial Networks to the design of an urban block. The research presents a flexible model able to adapt to the morphological characteristics of a city. This method does not define explicitly any of the parameters of an urban block typical for a city, the algorithm learns them from the existing urban context. This approach has been applied to the cities with different morphology: Milan, Amsterdam, Tallinn, Turin, and Bengaluru in order to see the performance of the model and the possibility of style translation between different cities. The data are gathered from Openstreetmap and Open Data portals of the cities. This research presents the results of the experiments and their quantitative and qualitative evaluation.
Synthetic 3D Data Generation Pipeline for Geometric Deep Learning in Architecture
Apr 26, 2021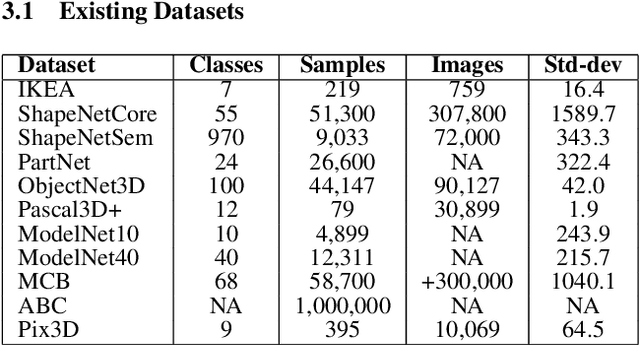
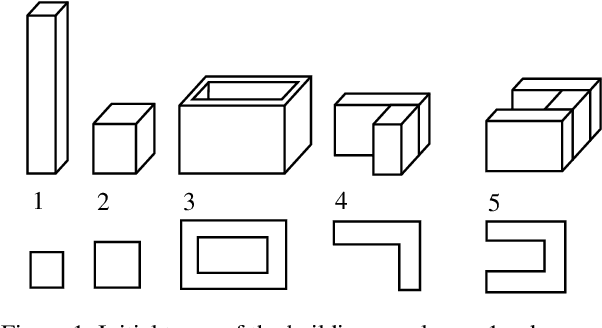
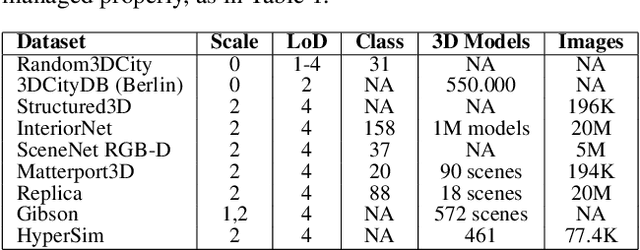
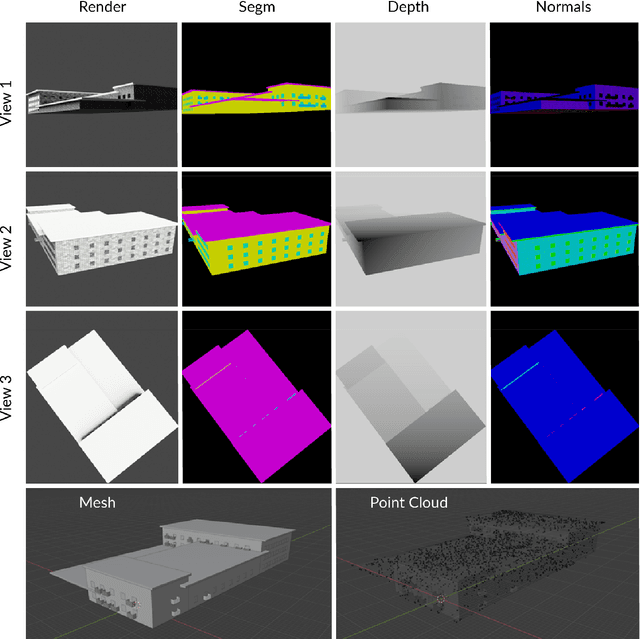
With the growing interest in deep learning algorithms and computational design in the architectural field, the need for large, accessible and diverse architectural datasets increases. We decided to tackle this problem by constructing a field-specific synthetic data generation pipeline that generates an arbitrary amount of 3D data along with the associated 2D and 3D annotations. The variety of annotations, the flexibility to customize the generated building and dataset parameters make this framework suitable for multiple deep learning tasks, including geometric deep learning that requires direct 3D supervision. Creating our building data generation pipeline we leveraged architectural knowledge from experts in order to construct a framework that would be modular, extendable and would provide a sufficient amount of class-balanced data samples. Moreover, we purposefully involve the researcher in the dataset customization allowing the introduction of additional building components, material textures, building classes, number and type of annotations as well as the number of views per 3D model sample. In this way, the framework would satisfy different research requirements and would be adaptable to a large variety of tasks. All code and data are made publicly available.