 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScandEval: A Benchmark for Scandinavian Natural Language Processing
Paper and Code
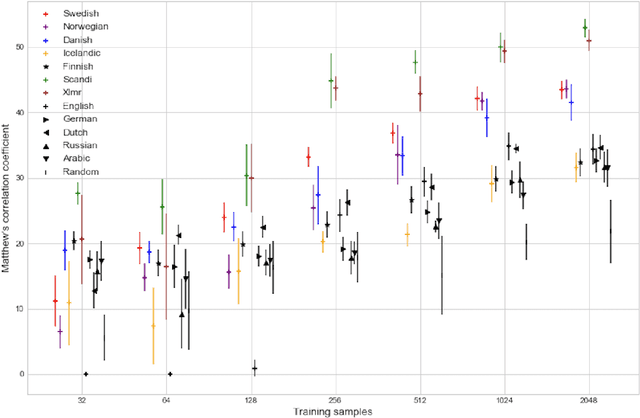


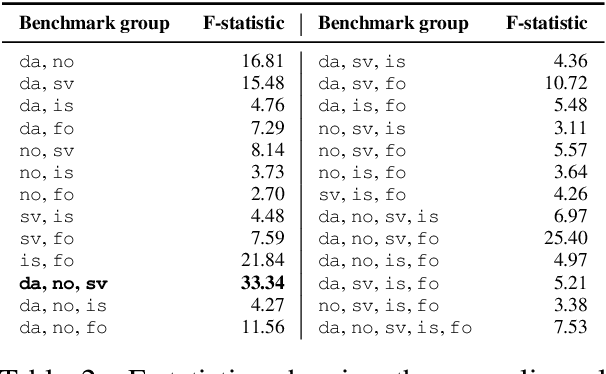
This paper introduces a Scandinavian benchmarking platform, ScandEval, which can benchmark any pretrained model on four different tasks in the Scandinavian languages. The datasets used in two of the tasks, linguistic acceptability and question answering, are new. We develop and release a Python package and command-line interface, scandeval, which can benchmark any model that has been uploaded to the Hugging Face Hub, with reproducible results. Using this package, we benchmark more than 100 Scandinavian or multilingual models and present the results of these in an interactive online leaderboard, as well as provide an analysis of the results. The analysis shows that there is substantial cross-lingual transfer among the Mainland Scandinavian languages (Danish, Swedish and Norwegian), with limited cross-lingual transfer between the group of Mainland Scandinavian languages and the group of Insular Scandinavian languages (Icelandic and Faroese). The benchmarking results also show that the investment in language technology in Norway, Sweden and Denmark has led to language models that outperform massively multilingual models such as XLM-RoBERTa and mDeBERTaV3. We release the source code for both the package and leaderboard.