 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByte-Level Grammatical Error Correction Using Synthetic and Curated Corpora
May 29, 2023



Grammatical error correction (GEC) is the task of correcting typos, spelling, punctuation and grammatical issues in text. Approaching the problem as a sequence-to-sequence task, we compare the use of a common subword unit vocabulary and byte-level encoding. Initial synthetic training data is created using an error-generating pipeline, and used for finetuning two subword-level models and one byte-level model. Models are then finetuned further on hand-corrected error corpora, including texts written by children, university students, dyslexic and second-language writers, and evaluated over different error types and origins. We show that a byte-level model enables higher correction quality than a subword approach, not only for simple spelling errors, but also for more complex semantic, stylistic and grammatical issues. In particular, initial training on synthetic corpora followed by finetuning on a relatively small parallel corpus of real-world errors helps the byte-level model correct a wide range of commonly occurring errors. Our experiments are run for the Icelandic language but should hold for other similar languages, particularly morphologically rich ones.
A Warm Start and a Clean Crawled Corpus -- A Recipe for Good Language Models
Jan 18, 2022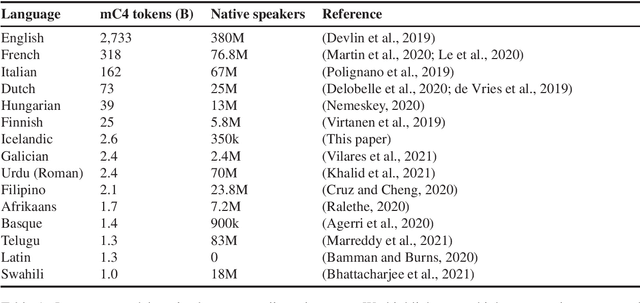
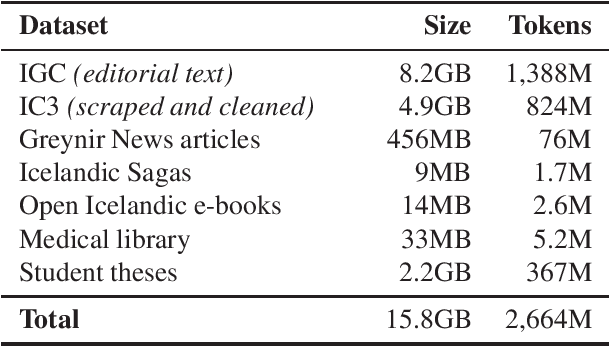

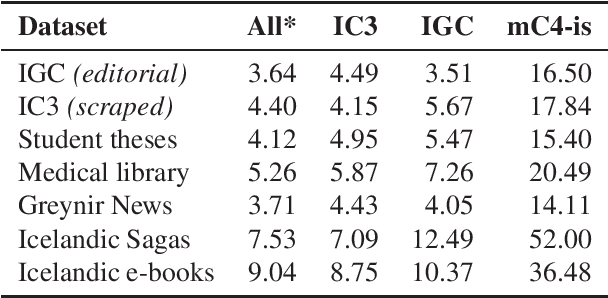
We train several language models for Icelandic, including IceBERT, that achieve state-of-the-art performance in a variety of downstream tasks, including part-of-speech tagging, named entity recognition, grammatical error detection and constituency parsing. To train the models we introduce a new corpus of Icelandic text, the Icelandic Common Crawl Corpus (IC3), a collection of high quality texts found online by targeting the Icelandic top-level-domain (TLD). Several other public data sources are also collected for a total of 16GB of Icelandic text. To enhance the evaluation of model performance and to raise the bar in baselines for Icelandic, we translate and adapt the WinoGrande dataset for co-reference resolution. Through these efforts we demonstrate that a properly cleaned crawled corpus is sufficient to achieve state-of-the-art results in NLP applications for low to medium resource languages, by comparison with models trained on a curated corpus. We further show that initializing models using existing multilingual models can lead to state-of-the-art results for some downstream tasks.
Miðeind's WMT 2021 submission
Sep 15, 2021
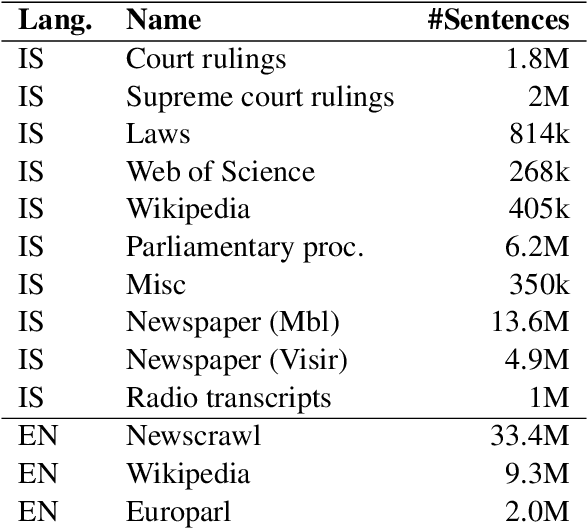

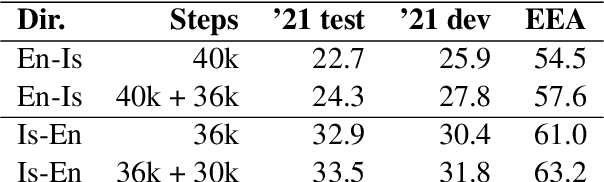
We present Mi{\dh}eind's submission for the English$\to$Icelandic and Icelandic$\to$English subsets of the 2021 WMT news translation task. Transformer-base models are trained for translation on parallel data to generate backtranslations iteratively. A pretrained mBART-25 model is then adapted for translation using parallel data as well as the last backtranslation iteration. This adapted pretrained model is then used to re-generate backtranslations, and the training of the adapted model is continued.
Icelandic Parallel Abstracts Corpus
Aug 11, 2021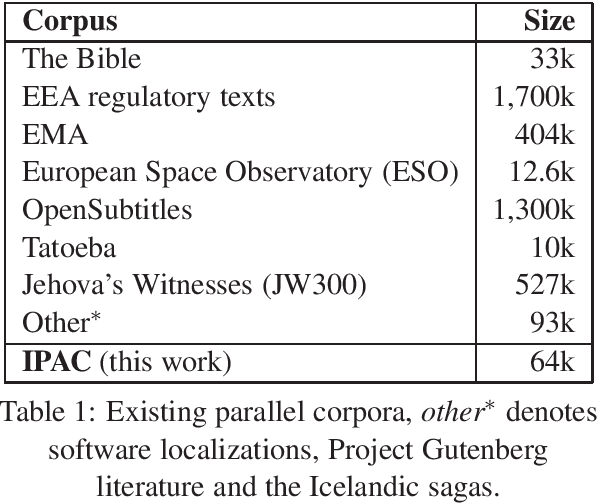

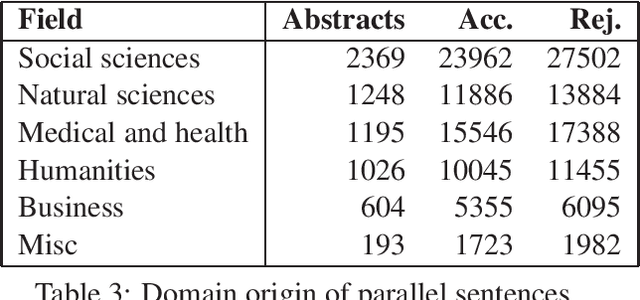

We present a new Icelandic-English parallel corpus, the Icelandic Parallel Abstracts Corpus (IPAC), composed of abstracts from student theses and dissertations. The texts were collected from the Skemman repository which keeps records of all theses, dissertations and final projects from students at Icelandic universities. The corpus was aligned based on sentence-level BLEU scores, in both translation directions, from NMT models using Bleualign. The result is a corpus of 64k sentence pairs from over 6 thousand parallel abstracts.