 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline learning of long-range dependencies
May 25, 2023Online learning holds the promise of enabling efficient long-term credit assignment in recurrent neural networks. However, current algorithms fall short of offline backpropagation by either not being scalable or failing to learn long-range dependencies. Here we present a high-performance online learning algorithm that merely doubles the memory and computational requirements of a single inference pass. We achieve this by leveraging independent recurrent modules in multi-layer networks, an architectural motif that has recently been shown to be particularly powerful. Experiments on synthetic memory problems and on the challenging long-range arena benchmark suite reveal that our algorithm performs competitively, establishing a new standard for what can be achieved through online learning. This ability to learn long-range dependencies offers a new perspective on learning in the brain and opens a promising avenue in neuromorphic computing.
Random initialisations performing above chance and how to find them
Sep 15, 2022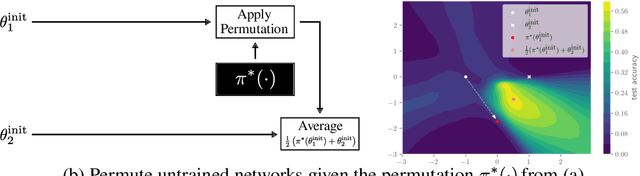
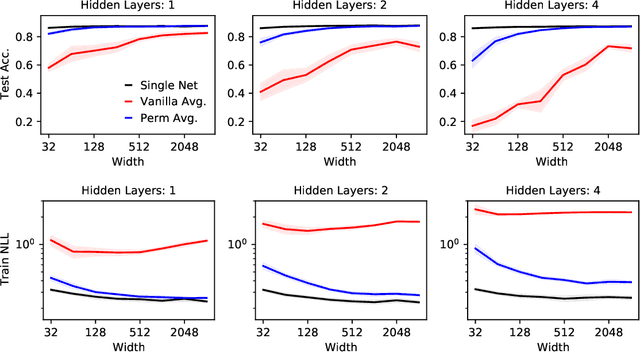
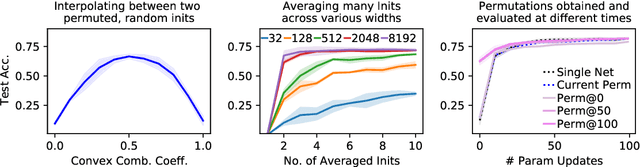
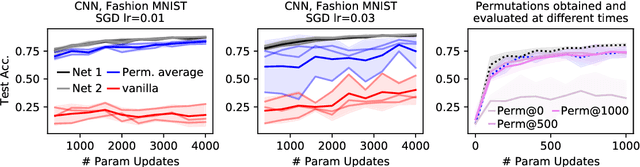
Neural networks trained with stochastic gradient descent (SGD) starting from different random initialisations typically find functionally very similar solutions, raising the question of whether there are meaningful differences between different SGD solutions. Entezari et al. recently conjectured that despite different initialisations, the solutions found by SGD lie in the same loss valley after taking into account the permutation invariance of neural networks. Concretely, they hypothesise that any two solutions found by SGD can be permuted such that the linear interpolation between their parameters forms a path without significant increases in loss. Here, we use a simple but powerful algorithm to find such permutations that allows us to obtain direct empirical evidence that the hypothesis is true in fully connected networks. Strikingly, we find that two networks already live in the same loss valley at the time of initialisation and averaging their random, but suitably permuted initialisation performs significantly above chance. In contrast, for convolutional architectures, our evidence suggests that the hypothesis does not hold. Especially in a large learning rate regime, SGD seems to discover diverse modes.
Open-Ended Reinforcement Learning with Neural Reward Functions
Feb 16, 2022
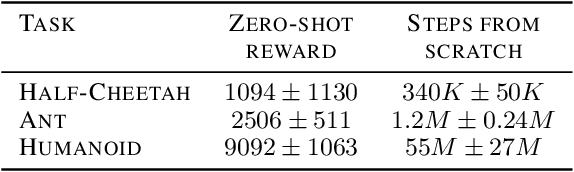


Inspired by the great success of unsupervised learning in Computer Vision and Natural Language Processing, the Reinforcement Learning community has recently started to focus more on unsupervised discovery of skills. Most current approaches, like DIAYN or DADS, optimize some form of mutual information objective. We propose a different approach that uses reward functions encoded by neural networks. These are trained iteratively to reward more complex behavior. In high-dimensional robotic environments our approach learns a wide range of interesting skills including front-flips for Half-Cheetah and one-legged running for Humanoid. In the pixel-based Montezuma's Revenge environment our method also works with minimal changes and it learns complex skills that involve interacting with items and visiting diverse locations. A web version of this paper which shows animations for the different skills is available in https://as.inf.ethz.ch/research/open_ended_RL/main.html