 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale leads to compositional generalization
Jul 09, 2025Can neural networks systematically capture discrete, compositional task structure despite their continuous, distributed nature? The impressive capabilities of large-scale neural networks suggest that the answer to this question is yes. However, even for the most capable models, there are still frequent failure cases that raise doubts about their compositionality. Here, we seek to understand what it takes for a standard neural network to generalize over tasks that share compositional structure. We find that simply scaling data and model size leads to compositional generalization. We show that this holds across different task encodings as long as the training distribution sufficiently covers the task space. In line with this finding, we prove that standard multilayer perceptrons can approximate a general class of compositional task families to arbitrary precision using only a linear number of neurons with respect to the number of task modules. Finally, we uncover that if networks successfully compositionally generalize, the constituents of a task can be linearly decoded from their hidden activations. We show that this metric correlates with failures of text-to-image generation models to compose known concepts.
When can transformers compositionally generalize in-context?
Jul 17, 2024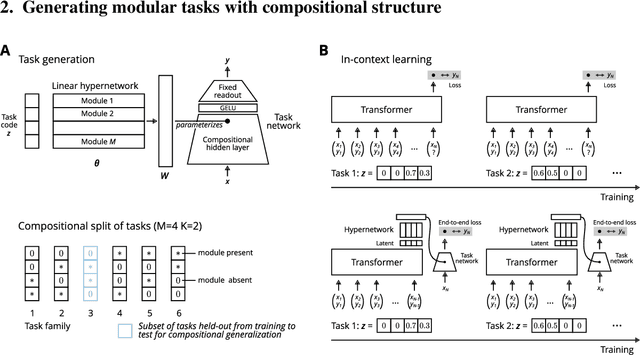

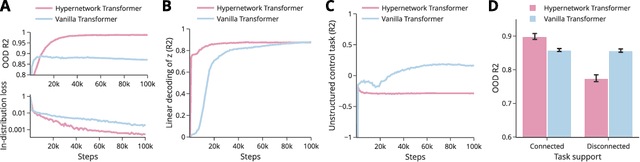

Many tasks can be composed from a few independent components. This gives rise to a combinatorial explosion of possible tasks, only some of which might be encountered during training. Under what circumstances can transformers compositionally generalize from a subset of tasks to all possible combinations of tasks that share similar components? Here we study a modular multitask setting that allows us to precisely control compositional structure in the data generation process. We present evidence that transformers learning in-context struggle to generalize compositionally on this task despite being in principle expressive enough to do so. Compositional generalization becomes possible only when introducing a bottleneck that enforces an explicit separation between task inference and task execution.
Attention as a Hypernetwork
Jun 09, 2024



Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
Discovering modular solutions that generalize compositionally
Dec 22, 2023

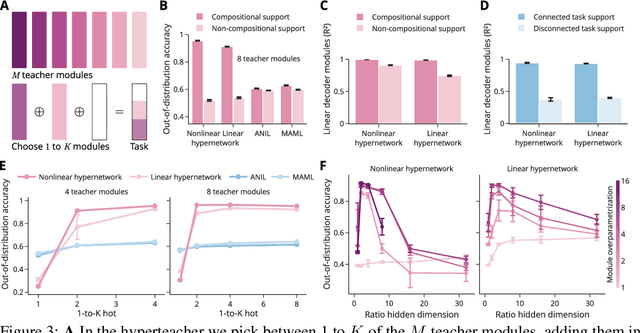
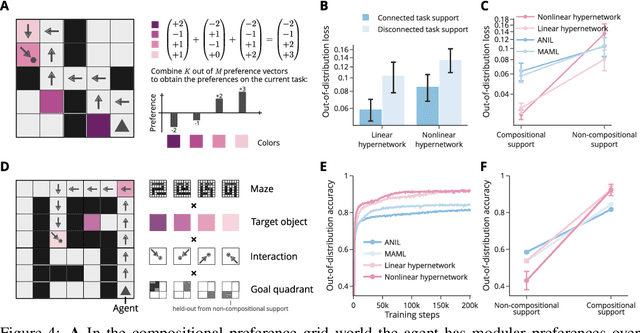
Many complex tasks and environments can be decomposed into simpler, independent parts. Discovering such underlying compositional structure has the potential to expedite adaptation and enable compositional generalization. Despite progress, our most powerful systems struggle to compose flexibly. While most of these systems are monolithic, modularity promises to allow capturing the compositional nature of many tasks. However, it is unclear under which circumstances modular systems discover this hidden compositional structure. To shed light on this question, we study a teacher-student setting with a modular teacher where we have full control over the composition of ground truth modules. This allows us to relate the problem of compositional generalization to that of identification of the underlying modules. We show theoretically that identification up to linear transformation purely from demonstrations is possible in hypernetworks without having to learn an exponential number of module combinations. While our theory assumes the infinite data limit, in an extensive empirical study we demonstrate how meta-learning from finite data can discover modular solutions that generalize compositionally in modular but not monolithic architectures. We further show that our insights translate outside the teacher-student setting and demonstrate that in tasks with compositional preferences and tasks with compositional goals hypernetworks can discover modular policies that compositionally generalize.
Would I have gotten that reward? Long-term credit assignment by counterfactual contribution analysis
Jun 29, 2023



To make reinforcement learning more sample efficient, we need better credit assignment methods that measure an action's influence on future rewards. Building upon Hindsight Credit Assignment (HCA), we introduce Counterfactual Contribution Analysis (COCOA), a new family of model-based credit assignment algorithms. Our algorithms achieve precise credit assignment by measuring the contribution of actions upon obtaining subsequent rewards, by quantifying a counterfactual query: "Would the agent still have reached this reward if it had taken another action?". We show that measuring contributions w.r.t. rewarding states, as is done in HCA, results in spurious estimates of contributions, causing HCA to degrade towards the high-variance REINFORCE estimator in many relevant environments. Instead, we measure contributions w.r.t. rewards or learned representations of the rewarding objects, resulting in gradient estimates with lower variance. We run experiments on a suite of problems specifically designed to evaluate long-term credit assignment capabilities. By using dynamic programming, we measure ground-truth policy gradients and show that the improved performance of our new model-based credit assignment methods is due to lower bias and variance compared to HCA and common baselines. Our results demonstrate how modeling action contributions towards rewarding outcomes can be leveraged for credit assignment, opening a new path towards sample-efficient reinforcement learning.
Online learning of long-range dependencies
May 25, 2023Online learning holds the promise of enabling efficient long-term credit assignment in recurrent neural networks. However, current algorithms fall short of offline backpropagation by either not being scalable or failing to learn long-range dependencies. Here we present a high-performance online learning algorithm that merely doubles the memory and computational requirements of a single inference pass. We achieve this by leveraging independent recurrent modules in multi-layer networks, an architectural motif that has recently been shown to be particularly powerful. Experiments on synthetic memory problems and on the challenging long-range arena benchmark suite reveal that our algorithm performs competitively, establishing a new standard for what can be achieved through online learning. This ability to learn long-range dependencies offers a new perspective on learning in the brain and opens a promising avenue in neuromorphic computing.
Random initialisations performing above chance and how to find them
Sep 15, 2022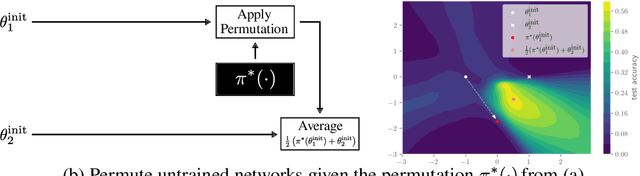
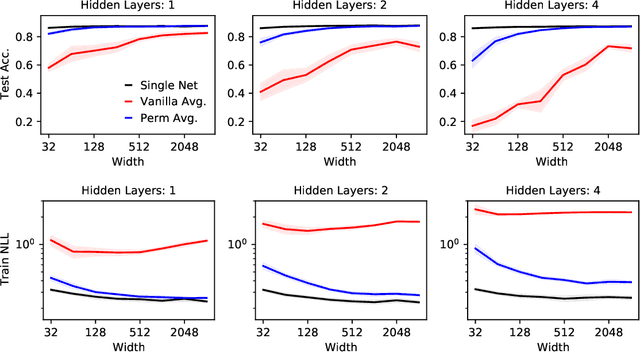
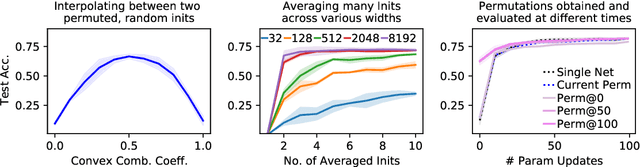
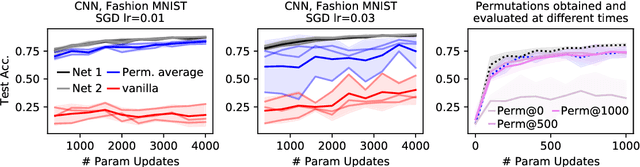
Neural networks trained with stochastic gradient descent (SGD) starting from different random initialisations typically find functionally very similar solutions, raising the question of whether there are meaningful differences between different SGD solutions. Entezari et al. recently conjectured that despite different initialisations, the solutions found by SGD lie in the same loss valley after taking into account the permutation invariance of neural networks. Concretely, they hypothesise that any two solutions found by SGD can be permuted such that the linear interpolation between their parameters forms a path without significant increases in loss. Here, we use a simple but powerful algorithm to find such permutations that allows us to obtain direct empirical evidence that the hypothesis is true in fully connected networks. Strikingly, we find that two networks already live in the same loss valley at the time of initialisation and averaging their random, but suitably permuted initialisation performs significantly above chance. In contrast, for convolutional architectures, our evidence suggests that the hypothesis does not hold. Especially in a large learning rate regime, SGD seems to discover diverse modes.
Learning where to learn: Gradient sparsity in meta and continual learning
Oct 27, 2021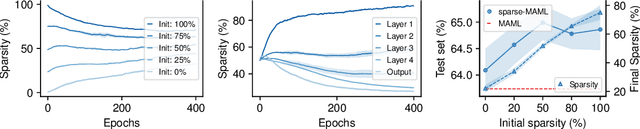
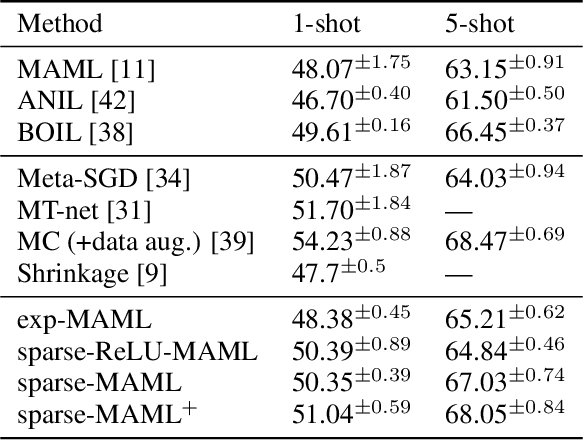
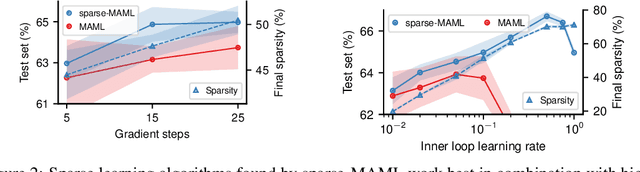
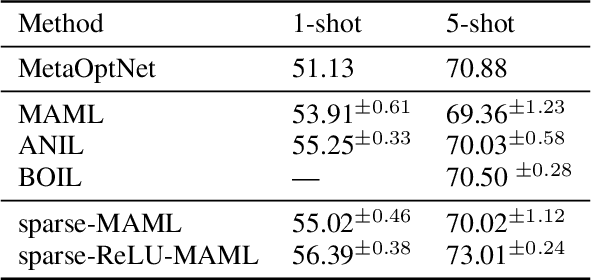
Finding neural network weights that generalize well from small datasets is difficult. A promising approach is to learn a weight initialization such that a small number of weight changes results in low generalization error. We show that this form of meta-learning can be improved by letting the learning algorithm decide which weights to change, i.e., by learning where to learn. We find that patterned sparsity emerges from this process, with the pattern of sparsity varying on a problem-by-problem basis. This selective sparsity results in better generalization and less interference in a range of few-shot and continual learning problems. Moreover, we find that sparse learning also emerges in a more expressive model where learning rates are meta-learned. Our results shed light on an ongoing debate on whether meta-learning can discover adaptable features and suggest that learning by sparse gradient descent is a powerful inductive bias for meta-learning systems.
A contrastive rule for meta-learning
Apr 19, 2021


Meta-learning algorithms leverage regularities that are present on a set of tasks to speed up and improve the performance of a subsidiary learning process. Recent work on deep neural networks has shown that prior gradient-based learning of meta-parameters can greatly improve the efficiency of subsequent learning. Here, we present a biologically plausible meta-learning algorithm based on equilibrium propagation. Instead of explicitly differentiating the learning process, our contrastive meta-learning rule estimates meta-parameter gradients by executing the subsidiary process more than once. This avoids reversing the learning dynamics in time and computing second-order derivatives. In spite of this, and unlike previous first-order methods, our rule recovers an arbitrarily accurate meta-parameter update given enough compute. We establish theoretical bounds on its performance and present experiments on a set of standard benchmarks and neural network architectures.