 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale leads to compositional generalization
Jul 09, 2025Can neural networks systematically capture discrete, compositional task structure despite their continuous, distributed nature? The impressive capabilities of large-scale neural networks suggest that the answer to this question is yes. However, even for the most capable models, there are still frequent failure cases that raise doubts about their compositionality. Here, we seek to understand what it takes for a standard neural network to generalize over tasks that share compositional structure. We find that simply scaling data and model size leads to compositional generalization. We show that this holds across different task encodings as long as the training distribution sufficiently covers the task space. In line with this finding, we prove that standard multilayer perceptrons can approximate a general class of compositional task families to arbitrary precision using only a linear number of neurons with respect to the number of task modules. Finally, we uncover that if networks successfully compositionally generalize, the constituents of a task can be linearly decoded from their hidden activations. We show that this metric correlates with failures of text-to-image generation models to compose known concepts.
SIGHT: Single-Image Conditioned Generation of Hand Trajectories for Hand-Object Interaction
Mar 28, 2025We introduce a novel task of generating realistic and diverse 3D hand trajectories given a single image of an object, which could be involved in a hand-object interaction scene or pictured by itself. When humans grasp an object, appropriate trajectories naturally form in our minds to use it for specific tasks. Hand-object interaction trajectory priors can greatly benefit applications in robotics, embodied AI, augmented reality and related fields. However, synthesizing realistic and appropriate hand trajectories given a single object or hand-object interaction image is a highly ambiguous task, requiring to correctly identify the object of interest and possibly even the correct interaction among many possible alternatives. To tackle this challenging problem, we propose the SIGHT-Fusion system, consisting of a curated pipeline for extracting visual features of hand-object interaction details from egocentric videos involving object manipulation, and a diffusion-based conditional motion generation model processing the extracted features. We train our method given video data with corresponding hand trajectory annotations, without supervision in the form of action labels. For the evaluation, we establish benchmarks utilizing the first-person FPHAB and HOI4D datasets, testing our method against various baselines and using multiple metrics. We also introduce task simulators for executing the generated hand trajectories and reporting task success rates as an additional metric. Experiments show that our method generates more appropriate and realistic hand trajectories than baselines and presents promising generalization capability on unseen objects. The accuracy of the generated hand trajectories is confirmed in a physics simulation setting, showcasing the authenticity of the created sequences and their applicability in downstream uses.
When can transformers compositionally generalize in-context?
Jul 17, 2024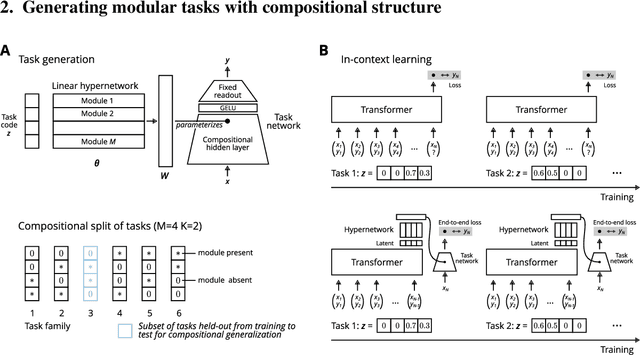

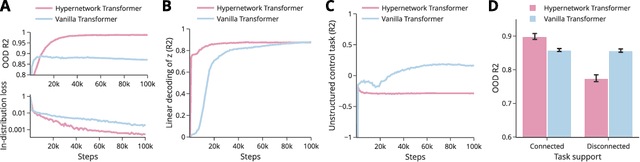

Many tasks can be composed from a few independent components. This gives rise to a combinatorial explosion of possible tasks, only some of which might be encountered during training. Under what circumstances can transformers compositionally generalize from a subset of tasks to all possible combinations of tasks that share similar components? Here we study a modular multitask setting that allows us to precisely control compositional structure in the data generation process. We present evidence that transformers learning in-context struggle to generalize compositionally on this task despite being in principle expressive enough to do so. Compositional generalization becomes possible only when introducing a bottleneck that enforces an explicit separation between task inference and task execution.