 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Encoding Dexterous Robotic Manipulation Priors Learned From Egocentric Videos
Apr 08, 2025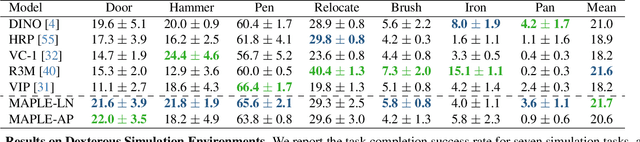

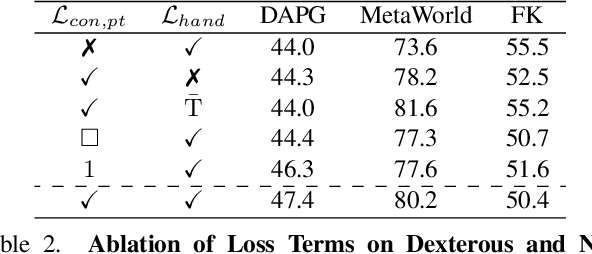
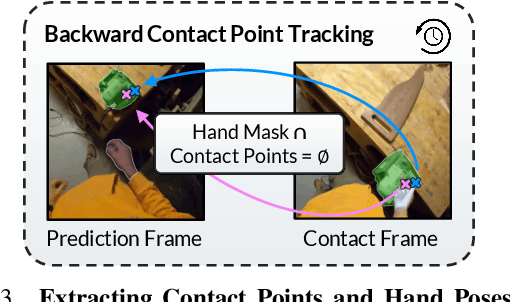
Large-scale egocentric video datasets capture diverse human activities across a wide range of scenarios, offering rich and detailed insights into how humans interact with objects, especially those that require fine-grained dexterous control. Such complex, dexterous skills with precise controls are crucial for many robotic manipulation tasks, yet are often insufficiently addressed by traditional data-driven approaches to robotic manipulation. To address this gap, we leverage manipulation priors learned from large-scale egocentric video datasets to improve policy learning for dexterous robotic manipulation tasks. We present MAPLE, a novel method for dexterous robotic manipulation that exploits rich manipulation priors to enable efficient policy learning and better performance on diverse, complex manipulation tasks. Specifically, we predict hand-object contact points and detailed hand poses at the moment of hand-object contact and use the learned features to train policies for downstream manipulation tasks. Experimental results demonstrate the effectiveness of MAPLE across existing simulation benchmarks, as well as a newly designed set of challenging simulation tasks, which require fine-grained object control and complex dexterous skills. The benefits of MAPLE are further highlighted in real-world experiments using a dexterous robotic hand, whereas simultaneous evaluation across both simulation and real-world experiments has remained underexplored in prior work.
SIGHT: Single-Image Conditioned Generation of Hand Trajectories for Hand-Object Interaction
Mar 28, 2025We introduce a novel task of generating realistic and diverse 3D hand trajectories given a single image of an object, which could be involved in a hand-object interaction scene or pictured by itself. When humans grasp an object, appropriate trajectories naturally form in our minds to use it for specific tasks. Hand-object interaction trajectory priors can greatly benefit applications in robotics, embodied AI, augmented reality and related fields. However, synthesizing realistic and appropriate hand trajectories given a single object or hand-object interaction image is a highly ambiguous task, requiring to correctly identify the object of interest and possibly even the correct interaction among many possible alternatives. To tackle this challenging problem, we propose the SIGHT-Fusion system, consisting of a curated pipeline for extracting visual features of hand-object interaction details from egocentric videos involving object manipulation, and a diffusion-based conditional motion generation model processing the extracted features. We train our method given video data with corresponding hand trajectory annotations, without supervision in the form of action labels. For the evaluation, we establish benchmarks utilizing the first-person FPHAB and HOI4D datasets, testing our method against various baselines and using multiple metrics. We also introduce task simulators for executing the generated hand trajectories and reporting task success rates as an additional metric. Experiments show that our method generates more appropriate and realistic hand trajectories than baselines and presents promising generalization capability on unseen objects. The accuracy of the generated hand trajectories is confirmed in a physics simulation setting, showcasing the authenticity of the created sequences and their applicability in downstream uses.
Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction
Jan 22, 2023We study the task of object interaction anticipation in egocentric videos. Successful prediction of future actions and objects requires an understanding of the spatio-temporal context formed by past actions and object relationships. We propose TransFusion, a multimodal transformer-based architecture, that effectively makes use of the representational power of language by summarizing past actions concisely. TransFusion leverages pre-trained image captioning models and summarizes the caption, focusing on past actions and objects. This action context together with a single input frame is processed by a multimodal fusion module to forecast the next object interactions. Our model enables more efficient end-to-end learning by replacing dense video features with language representations, allowing us to benefit from knowledge encoded in large pre-trained models. Experiments on Ego4D and EPIC-KITCHENS-100 show the effectiveness of our multimodal fusion model and the benefits of using language-based context summaries. Our method outperforms state-of-the-art approaches by 40.4% in overall mAP on the Ego4D test set. We show the generality of TransFusion via experiments on EPIC-KITCHENS-100. Video and code are available at: https://eth-ait.github.io/transfusion-proj/.