 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Systematic Generalization in a Situated Agent
Paper and Code
Oct 28, 2019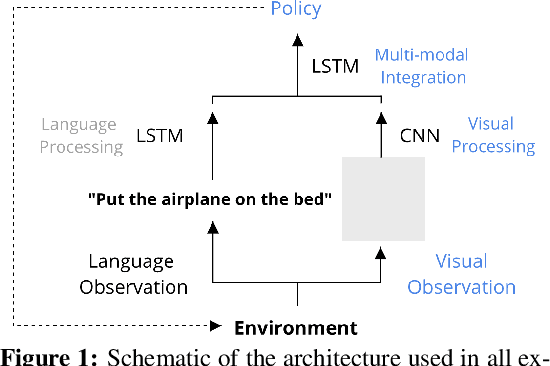
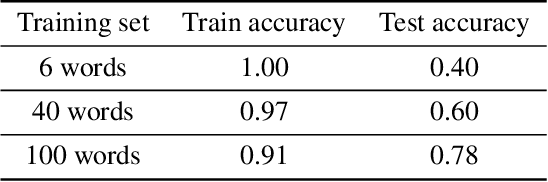
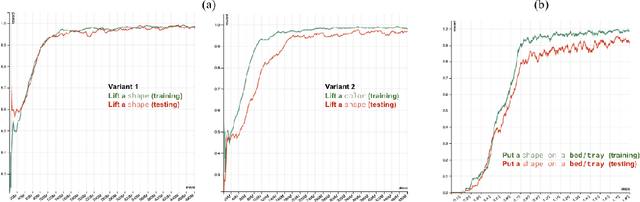
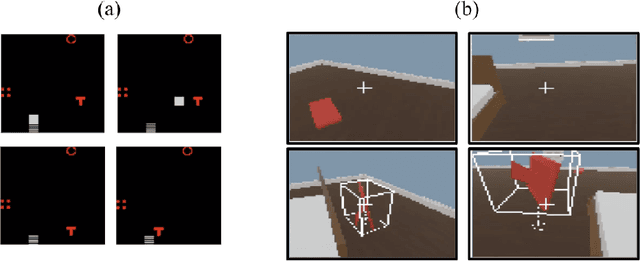
The question of whether deep neural networks are good at generalising beyond their immediate training experience is of critical importance for learning-based approaches to AI. Here, we demonstrate strong emergent systematic generalisation in a neural network agent and isolate the factors that support this ability. In environments ranging from a grid-world to a rich interactive 3D Unity room, we show that an agent can correctly exploit the compositional nature of a symbolic language to interpret never-seen-before instructions. We observe this capacity not only when instructions refer to object properties (colors and shapes) but also verb-like motor skills (lifting and putting) and abstract modifying operations (negation). We identify three factors that can contribute to this facility for systematic generalisation: (a) the number of object/word experiences in the training set; (b) the invariances afforded by a first-person, egocentric perspective; and (c) the variety of visual input experienced by an agent that perceives the world actively over time. Thus, while neural nets trained in idealised or reduced situations may fail to exhibit a compositional or systematic understanding of their experience, this competence can readily emerge when, like human learners, they have access to many examples of richly varying, multi-modal observations as they learn.