 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral or spatial? Leveraging both for speaker extraction in challenging data conditions
Dec 23, 2025This paper presents a robust multi-channel speaker extraction algorithm designed to handle inaccuracies in reference information. While existing approaches often rely solely on either spatial or spectral cues to identify the target speaker, our method integrates both sources of information to enhance robustness. A key aspect of our approach is its emphasis on stability, ensuring reliable performance even when one of the features is degraded or misleading. Given a noisy mixture and two potentially unreliable cues, a dedicated network is trained to dynamically balance their contributions-or disregard the less informative one when necessary. We evaluate the system under challenging conditions by simulating inference-time errors using a simple direction of arrival (DOA) estimator and a noisy spectral enrollment process. Experimental results demonstrate that the proposed model successfully extracts the desired speaker even in the presence of substantial reference inaccuracies.
End-to-End Multi-Microphone Speaker Extraction Using Relative Transfer Functions
Feb 10, 2025This paper introduces a multi-microphone method for extracting a desired speaker from a mixture involving multiple speakers and directional noise in a reverberant environment. In this work, we propose leveraging the instantaneous relative transfer function (RTF), estimated from a reference utterance recorded in the same position as the desired source. The effectiveness of the RTF-based spatial cue is compared with direction of arrival (DOA)-based spatial cue and the conventional spectral embedding. Experimental results in challenging acoustic scenarios demonstrate that using spatial cues yields better performance than the spectral-based cue and that the instantaneous RTF outperforms the DOA-based spatial cue.
A two-stage speaker extraction algorithm under adverse acoustic conditions using a single-microphone
Mar 13, 2023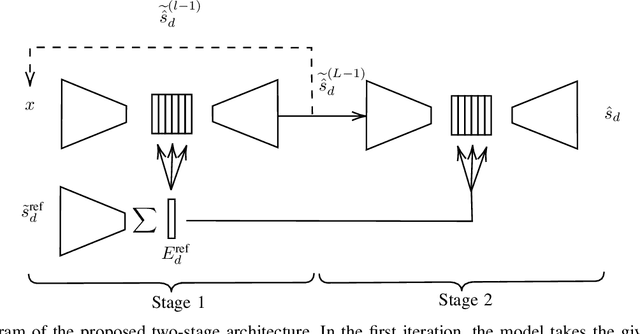

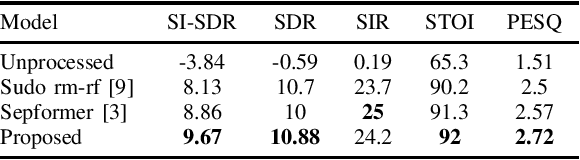
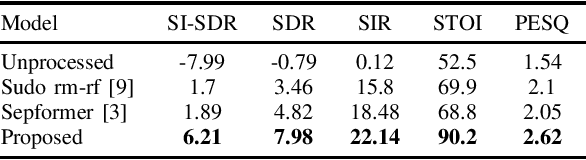
In this work, we present a two-stage method for speaker extraction under reverberant and noisy conditions. Given a reference signal of the desired speaker, the clean, but the still reverberant, desired speaker is first extracted from the noisy-mixed signal. In the second stage, the extracted signal is further enhanced by joint dereverberation and residual noise and interference reduction. The proposed architecture comprises two sub-networks, one for the extraction task and the second for the dereverberation task. We present a training strategy for this architecture and show that the performance of the proposed method is on par with other state-of-the-art (SOTA) methods when applied to the WHAMR! dataset. Furthermore, we present a new dataset with more realistic adverse acoustic conditions and show that our method outperforms the competing methods when applied to this dataset as well.
Single microphone speaker extraction using unified time-frequency Siamese-Unet
Mar 06, 2022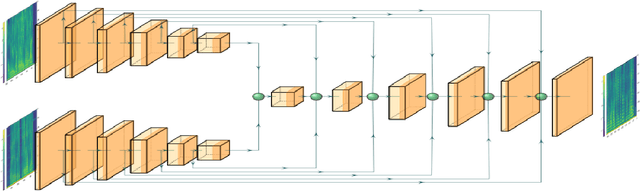
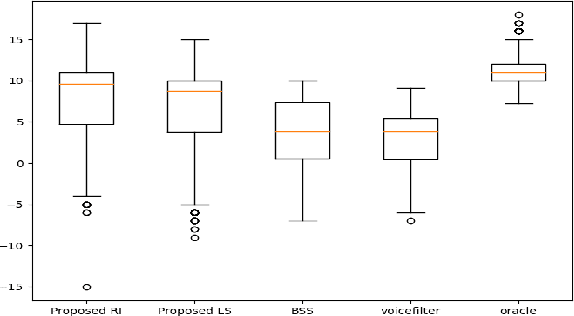
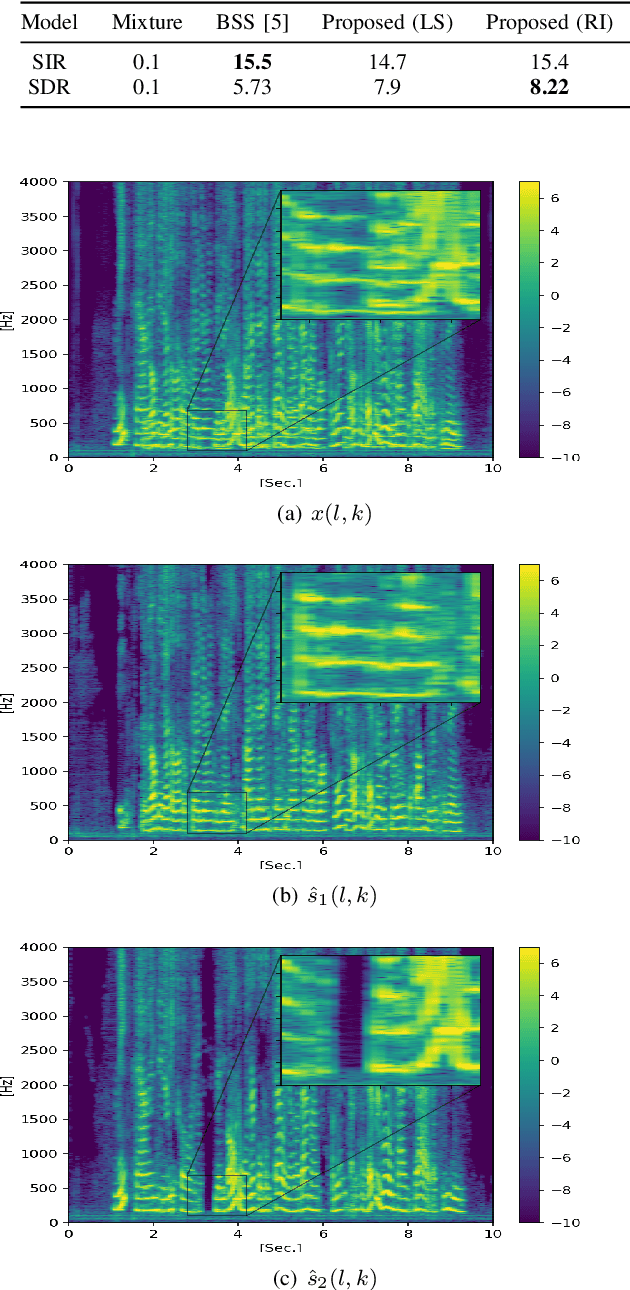

In this paper we present a unified time-frequency method for speaker extraction in clean and noisy conditions. Given a mixed signal, along with a reference signal, the common approaches for extracting the desired speaker are either applied in the time-domain or in the frequency-domain. In our approach, we propose a Siamese-Unet architecture that uses both representations. The Siamese encoders are applied in the frequency-domain to infer the embedding of the noisy and reference spectra, respectively. The concatenated representations are then fed into the decoder to estimate the real and imaginary components of the desired speaker, which are then inverse-transformed to the time-domain. The model is trained with the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) loss to exploit the time-domain information. The time-domain loss is also regularized with frequency-domain loss to preserve the speech patterns. Experimental results demonstrate that the unified approach is not only very easy to train, but also provides superior results as compared with state-of-the-art (SOTA) Blind Source Separation (BSS) methods, as well as commonly used speaker extraction approach.