 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLa Leaderboard: A Large Language Model Leaderboard for Spanish Varieties and Languages of Spain and Latin America
Jul 01, 2025Leaderboards showcase the current capabilities and limitations of Large Language Models (LLMs). To motivate the development of LLMs that represent the linguistic and cultural diversity of the Spanish-speaking community, we present La Leaderboard, the first open-source leaderboard to evaluate generative LLMs in languages and language varieties of Spain and Latin America. La Leaderboard is a community-driven project that aims to establish an evaluation standard for everyone interested in developing LLMs for the Spanish-speaking community. This initial version combines 66 datasets in Basque, Catalan, Galician, and different Spanish varieties, showcasing the evaluation results of 50 models. To encourage community-driven development of leaderboards in other languages, we explain our methodology, including guidance on selecting the most suitable evaluation setup for each downstream task. In particular, we provide a rationale for using fewer few-shot examples than typically found in the literature, aiming to reduce environmental impact and facilitate access to reproducible results for a broader research community.
A LLM-Based Ranking Method for the Evaluation of Automatic Counter-Narrative Generation
Jun 21, 2024
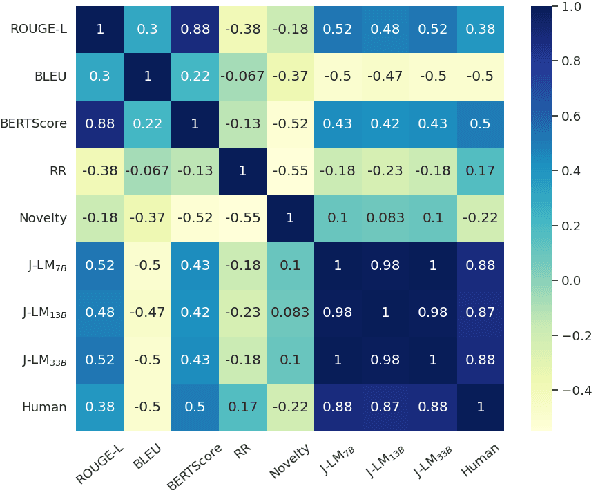


The proliferation of misinformation and harmful narratives in online discourse has underscored the critical need for effective Counter Narrative (CN) generation techniques. However, existing automatic evaluation methods often lack interpretability and fail to capture the nuanced relationship between generated CNs and human perception. Aiming to achieve a higher correlation with human judgments, this paper proposes a novel approach to asses generated CNs that consists on the use of a Large Language Model (LLM) as a evaluator. By comparing generated CNs pairwise in a tournament-style format, we establish a model ranking pipeline that achieves a correlation of $0.88$ with human preference. As an additional contribution, we leverage LLMs as zero-shot (ZS) CN generators and conduct a comparative analysis of chat, instruct, and base models, exploring their respective strengths and limitations. Through meticulous evaluation, including fine-tuning experiments, we elucidate the differences in performance and responsiveness to domain-specific data. We conclude that chat-aligned models in ZS are the best option for carrying out the task, provided they do not refuse to generate an answer due to security concerns.