 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartisanLens: A Multilingual Dataset of Hyperpartisan and Conspiratorial Immigration Narratives in European Media
Jan 07, 2026Detecting hyperpartisan narratives and Population Replacement Conspiracy Theories (PRCT) is essential to addressing the spread of misinformation. These complex narratives pose a significant threat, as hyperpartisanship drives political polarisation and institutional distrust, while PRCTs directly motivate real-world extremist violence, making their identification critical for social cohesion and public safety. However, existing resources are scarce, predominantly English-centric, and often analyse hyperpartisanship, stance, and rhetorical bias in isolation rather than as interrelated aspects of political discourse. To bridge this gap, we introduce \textsc{PartisanLens}, the first multilingual dataset of \num{1617} hyperpartisan news headlines in Spanish, Italian, and Portuguese, annotated in multiple political discourse aspects. We first evaluate the classification performance of widely used Large Language Models (LLMs) on this dataset, establishing robust baselines for the classification of hyperpartisan and PRCT narratives. In addition, we assess the viability of using LLMs as automatic annotators for this task, analysing their ability to approximate human annotation. Results highlight both their potential and current limitations. Next, moving beyond standard judgments, we explore whether LLMs can emulate human annotation patterns by conditioning them on socio-economic and ideological profiles that simulate annotator perspectives. At last, we provide our resources and evaluation, \textsc{PartisanLens} supports future research on detecting partisan and conspiratorial narratives in European contexts.
Are LLMs Enough for Hyperpartisan, Fake, Polarized and Harmful Content Detection? Evaluating In-Context Learning vs. Fine-Tuning
Sep 09, 2025
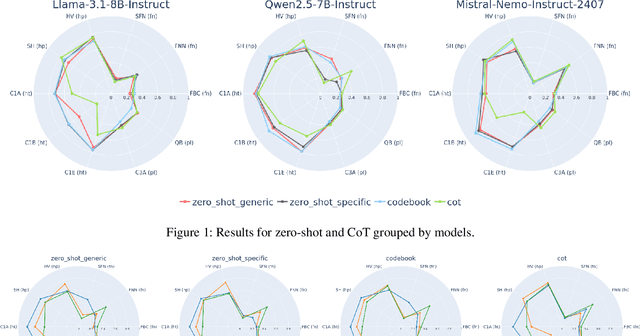
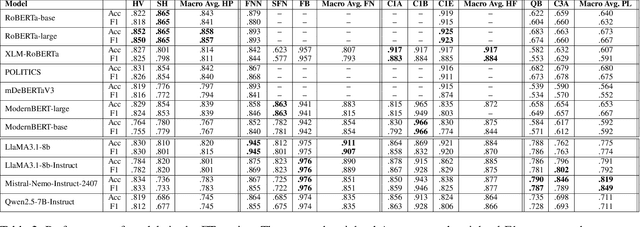
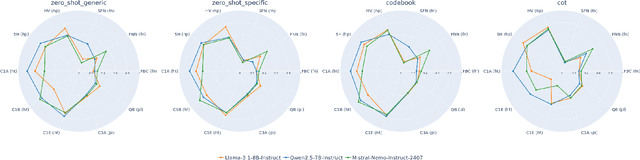
The spread of fake news, polarizing, politically biased, and harmful content on online platforms has been a serious concern. With large language models becoming a promising approach, however, no study has properly benchmarked their performance across different models, usage methods, and languages. This study presents a comprehensive overview of different Large Language Models adaptation paradigms for the detection of hyperpartisan and fake news, harmful tweets, and political bias. Our experiments spanned 10 datasets and 5 different languages (English, Spanish, Portuguese, Arabic and Bulgarian), covering both binary and multiclass classification scenarios. We tested different strategies ranging from parameter efficient Fine-Tuning of language models to a variety of different In-Context Learning strategies and prompts. These included zero-shot prompts, codebooks, few-shot (with both randomly-selected and diversely-selected examples using Determinantal Point Processes), and Chain-of-Thought. We discovered that In-Context Learning often underperforms when compared to Fine-Tuning a model. This main finding highlights the importance of Fine-Tuning even smaller models on task-specific settings even when compared to the largest models evaluated in an In-Context Learning setup - in our case LlaMA3.1-8b-Instruct, Mistral-Nemo-Instruct-2407 and Qwen2.5-7B-Instruct.
Truth Knows No Language: Evaluating Truthfulness Beyond English
Feb 13, 2025
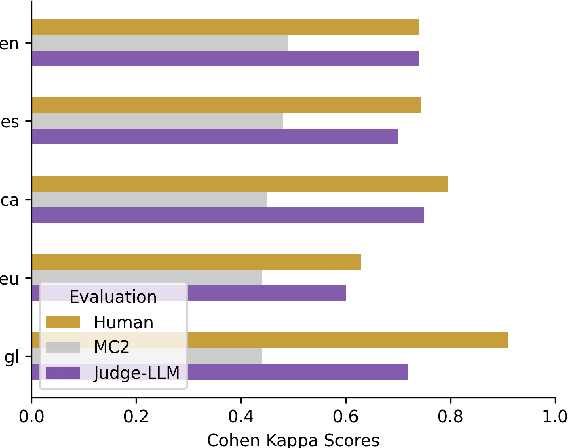
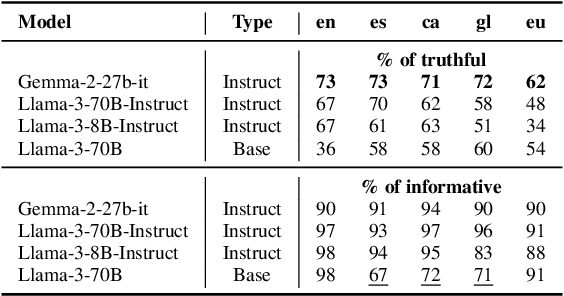
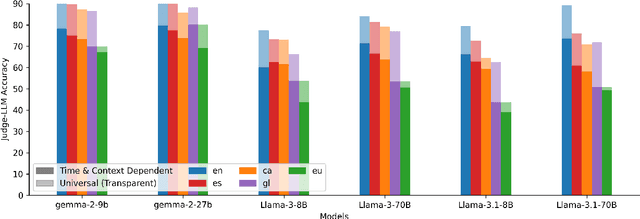
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations of large language models (LLMs) have primarily been conducted in English. However, the ability of LLMs to maintain truthfulness across languages remains under-explored. Our study evaluates 12 state-of-the-art open LLMs, comparing base and instruction-tuned models using human evaluation, multiple-choice metrics, and LLM-as-a-Judge scoring. Our findings reveal that, while LLMs perform best in English and worst in Basque (the lowest-resourced language), overall truthfulness discrepancies across languages are smaller than anticipated. Furthermore, we show that LLM-as-a-Judge correlates more closely with human judgments than multiple-choice metrics, and that informativeness plays a critical role in truthfulness assessment. Our results also indicate that machine translation provides a viable approach for extending truthfulness benchmarks to additional languages, offering a scalable alternative to professional translation. Finally, we observe that universal knowledge questions are better handled across languages than context- and time-dependent ones, highlighting the need for truthfulness evaluations that account for cultural and temporal variability. Dataset and code are publicly available under open licenses.
Open Generative Large Language Models for Galician
Jun 19, 2024Large language models (LLMs) have transformed natural language processing. Yet, their predominantly English-centric training has led to biases and performance disparities across languages. This imbalance marginalizes minoritized languages, making equitable access to NLP technologies more difficult for languages with lower resources, such as Galician. We present the first two generative LLMs focused on Galician to bridge this gap. These models, freely available as open-source resources, were trained using a GPT architecture with 1.3B parameters on a corpus of 2.1B words. Leveraging continual pretraining, we adapt to Galician two existing LLMs trained on larger corpora, thus mitigating the data constraints that would arise if the training were performed from scratch. The models were evaluated using human judgments and task-based datasets from standardized benchmarks. These evaluations reveal a promising performance, underscoring the importance of linguistic diversity in generative models.
Contextualized word senses: from attention to compositionality
Dec 01, 2023The neural architectures of language models are becoming increasingly complex, especially that of Transformers, based on the attention mechanism. Although their application to numerous natural language processing tasks has proven to be very fruitful, they continue to be models with little or no interpretability and explainability. One of the tasks for which they are best suited is the encoding of the contextual sense of words using contextualized embeddings. In this paper we propose a transparent, interpretable, and linguistically motivated strategy for encoding the contextual sense of words by modeling semantic compositionality. Particular attention is given to dependency relations and semantic notions such as selection preferences and paradigmatic classes. A partial implementation of the proposed model is carried out and compared with Transformer-based architectures for a given semantic task, namely the similarity calculation of word senses in context. The results obtained show that it is possible to be competitive with linguistically motivated models instead of using the black boxes underlying complex neural architectures.
Automatic Authorship Attribution in the Work of Tirso de Molina
Apr 01, 2023Automatic Authorship Attribution (AAA) is the result of applying tools and techniques from Digital Humanities to authorship attribution studies. Through a quantitative and statistical approach this discipline can draw further conclusions about renowned authorship issues which traditional critics have been dealing with for centuries, opening a new door to style comparison. The aim of this paper is to prove the potential of these tools and techniques by testing the authorship of five comedies traditionally attributed to Spanish playwright Tirso de Molina (1579-1648): La ninfa del cielo, El burlador de Sevilla, Tan largo me lo fiais, La mujer por fuerza and El condenado por desconfiado. To accomplish this purpose some experiments concerning clustering analysis by Stylo package from R and four distance measures are carried out on a corpus built with plays by Tirso, Andres de Claramonte (c. 1560-1626), Antonio Mira de Amescua (1577-1644) and Luis Velez de Guevara (1579-1644). The results obtained point to the denial of all the attributions to Tirso except for the case of La mujer por fuerza.
* 20 pages, 2 figures