 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth Knows No Language: Evaluating Truthfulness Beyond English
Feb 13, 2025
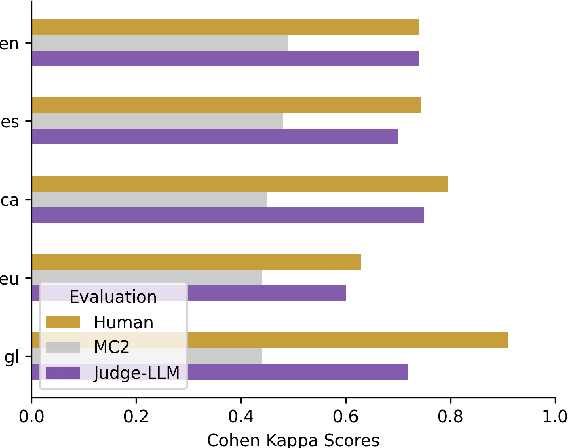
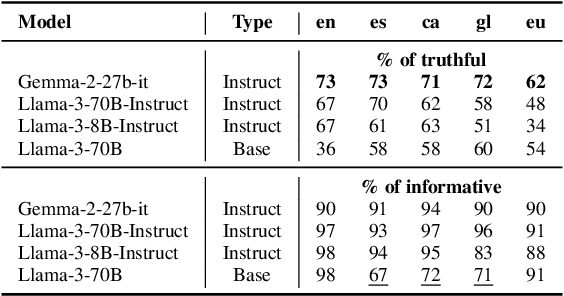
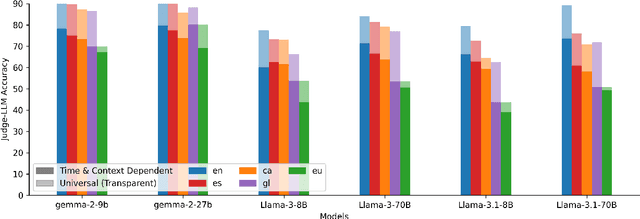
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations of large language models (LLMs) have primarily been conducted in English. However, the ability of LLMs to maintain truthfulness across languages remains under-explored. Our study evaluates 12 state-of-the-art open LLMs, comparing base and instruction-tuned models using human evaluation, multiple-choice metrics, and LLM-as-a-Judge scoring. Our findings reveal that, while LLMs perform best in English and worst in Basque (the lowest-resourced language), overall truthfulness discrepancies across languages are smaller than anticipated. Furthermore, we show that LLM-as-a-Judge correlates more closely with human judgments than multiple-choice metrics, and that informativeness plays a critical role in truthfulness assessment. Our results also indicate that machine translation provides a viable approach for extending truthfulness benchmarks to additional languages, offering a scalable alternative to professional translation. Finally, we observe that universal knowledge questions are better handled across languages than context- and time-dependent ones, highlighting the need for truthfulness evaluations that account for cultural and temporal variability. Dataset and code are publicly available under open licenses.