 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Generative Large Language Models for Galician
Jun 19, 2024Large language models (LLMs) have transformed natural language processing. Yet, their predominantly English-centric training has led to biases and performance disparities across languages. This imbalance marginalizes minoritized languages, making equitable access to NLP technologies more difficult for languages with lower resources, such as Galician. We present the first two generative LLMs focused on Galician to bridge this gap. These models, freely available as open-source resources, were trained using a GPT architecture with 1.3B parameters on a corpus of 2.1B words. Leveraging continual pretraining, we adapt to Galician two existing LLMs trained on larger corpora, thus mitigating the data constraints that would arise if the training were performed from scratch. The models were evaluated using human judgments and task-based datasets from standardized benchmarks. These evaluations reveal a promising performance, underscoring the importance of linguistic diversity in generative models.
A computational psycholinguistic evaluation of the syntactic abilities of Galician BERT models at the interface of dependency resolution and training time
Jun 06, 2022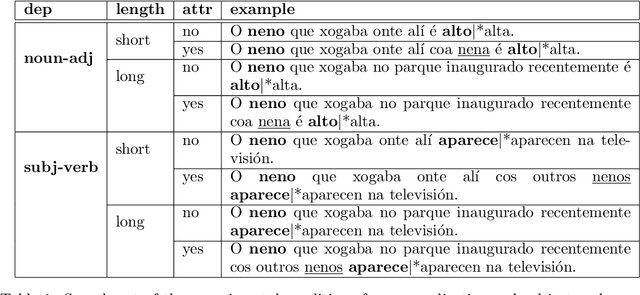
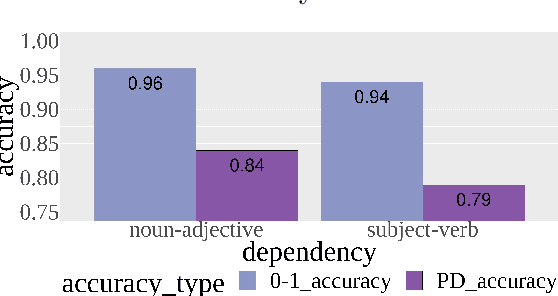

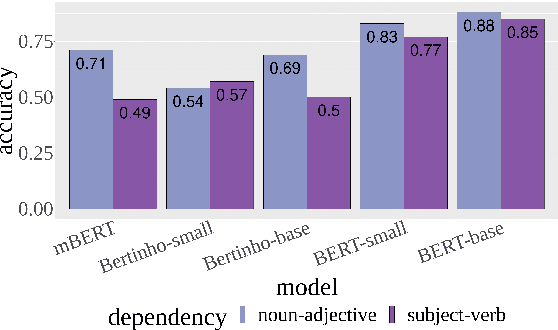
This paper explores the ability of Transformer models to capture subject-verb and noun-adjective agreement dependencies in Galician. We conduct a series of word prediction experiments in which we manipulate dependency length together with the presence of an attractor noun that acts as a lure. First, we evaluate the overall performance of the existing monolingual and multilingual models for Galician. Secondly, to observe the effects of the training process, we compare the different degrees of achievement of two monolingual BERT models at different training points. We also release their checkpoints and propose an alternative evaluation metric. Our results confirm previous findings by similar works that use the agreement prediction task and provide interesting insights into the number of training steps required by a Transformer model to solve long-distance dependencies.