 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes CLIP Benefit Visual Question Answering in the Medical Domain as Much as it Does in the General Domain?
Paper and Code
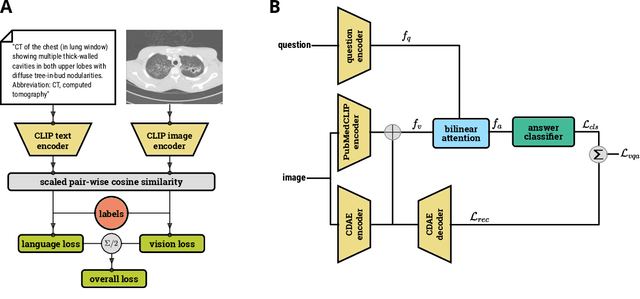
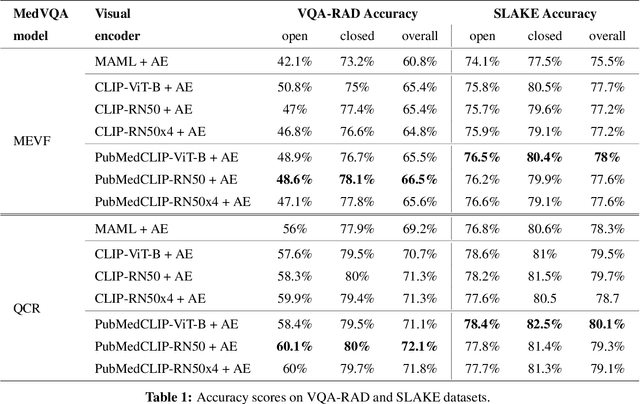
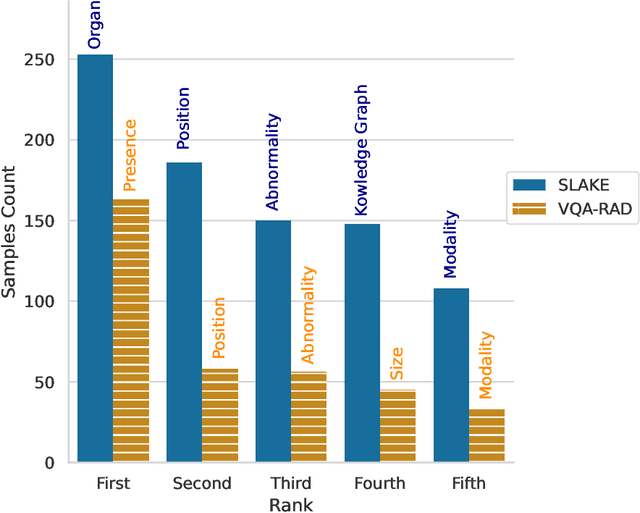
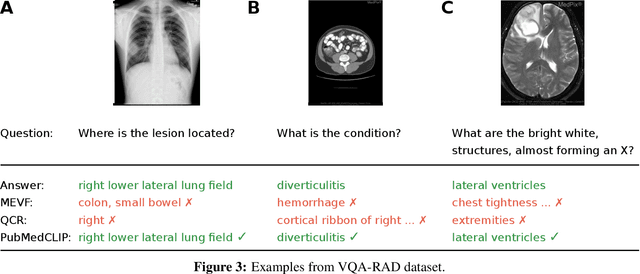
Contrastive Language--Image Pre-training (CLIP) has shown remarkable success in learning with cross-modal supervision from extensive amounts of image--text pairs collected online. Thus far, the effectiveness of CLIP has been investigated primarily in general-domain multimodal problems. This work evaluates the effectiveness of CLIP for the task of Medical Visual Question Answering (MedVQA). To this end, we present PubMedCLIP, a fine-tuned version of CLIP for the medical domain based on PubMed articles. Our experiments are conducted on two MedVQA benchmark datasets and investigate two MedVQA methods, MEVF (Mixture of Enhanced Visual Features) and QCR (Question answering via Conditional Reasoning). For each of these, we assess the merits of visual representation learning using PubMedCLIP, the original CLIP, and state-of-the-art MAML (Model-Agnostic Meta-Learning) networks pre-trained only on visual data. We open source the code for our MedVQA pipeline and pre-training PubMedCLIP. CLIP and PubMedCLIP achieve improvements in comparison to MAML's visual encoder. PubMedCLIP achieves the best results with gains in the overall accuracy of up to 3%. Individual examples illustrate the strengths of PubMedCLIP in comparison to the previously widely used MAML networks. Visual representation learning with language supervision in PubMedCLIP leads to noticeable improvements for MedVQA. Our experiments reveal distributional differences in the two MedVQA benchmark datasets that have not been imparted in previous work and cause different back-end visual encoders in PubMedCLIP to exhibit different behavior on these datasets. Moreover, we witness fundamental performance differences of VQA in general versus medical domains.