 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuddle-Fish: Exploring a Soft Floating Robot with Flapping Wings for Physical Interactions
Apr 02, 2025Flying robots, such as quadrotor drones, offer new possibilities for human-robot interaction but often pose safety risks due to fast-spinning propellers, rigid structures, and noise. In contrast, lighter-than-air flapping-wing robots, inspired by animal movement, offer a soft, quiet, and touch-safe alternative. Building on these advantages, we present \textit{Cuddle-Fish}, a soft, flapping-wing floating robot designed for safe, close-proximity interactions in indoor spaces. Through a user study with 24 participants, we explored their perceptions of the robot and experiences during a series of co-located demonstrations in which the robot moved near them. Results showed that participants felt safe, willingly engaged in touch-based interactions with the robot, and exhibited spontaneous affective behaviours, such as patting, stroking, hugging, and cheek-touching, without external prompting. They also reported positive emotional responses towards the robot. These findings suggest that the soft floating robot with flapping wings can serve as a novel and socially acceptable alternative to traditional rigid flying robots, opening new possibilities for companionship, play, and interactive experiences in everyday indoor environments.
Action Sensitivity Learning for the Ego4D Episodic Memory Challenge 2023
Jun 15, 2023This report presents ReLER submission to two tracks in the Ego4D Episodic Memory Benchmark in CVPR 2023, including Natural Language Queries and Moment Queries. This solution inherits from our proposed Action Sensitivity Learning framework (ASL) to better capture discrepant information of frames. Further, we incorporate a series of stronger video features and fusion strategies. Our method achieves an average mAP of 29.34, ranking 1st in Moment Queries Challenge, and garners 19.79 mean R1, ranking 2nd in Natural Language Queries Challenge. Our code will be released.
Action Sensitivity Learning for Temporal Action Localization
May 25, 2023Temporal action localization (TAL), which involves recognizing and locating action instances, is a challenging task in video understanding. Most existing approaches directly predict action classes and regress offsets to boundaries, while overlooking the discrepant importance of each frame. In this paper, we propose an Action Sensitivity Learning framework (ASL) to tackle this task, which aims to assess the value of each frame and then leverage the generated action sensitivity to recalibrate the training procedure. We first introduce a lightweight Action Sensitivity Evaluator to learn the action sensitivity at the class level and instance level, respectively. The outputs of the two branches are combined to reweight the gradient of the two sub-tasks. Moreover, based on the action sensitivity of each frame, we design an Action Sensitive Contrastive Loss to enhance features, where the action-aware frames are sampled as positive pairs to push away the action-irrelevant frames. The extensive studies on various action localization benchmarks (i.e., MultiThumos, Charades, Ego4D-Moment Queries v1.0, Epic-Kitchens 100, Thumos14 and ActivityNet1.3) show that ASL surpasses the state-of-the-art in terms of average-mAP under multiple types of scenarios, e.g., single-labeled, densely-labeled and egocentric.
Lana: A Language-Capable Navigator for Instruction Following and Generation
Mar 15, 2023
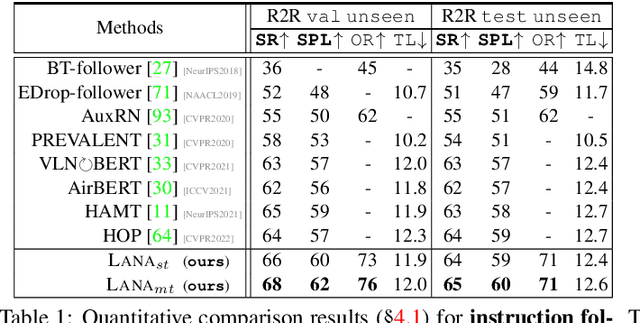


Recently, visual-language navigation (VLN) -- entailing robot agents to follow navigation instructions -- has shown great advance. However, existing literature put most emphasis on interpreting instructions into actions, only delivering "dumb" wayfinding agents. In this article, we devise LANA, a language-capable navigation agent which is able to not only execute human-written navigation commands, but also provide route descriptions to humans. This is achieved by simultaneously learning instruction following and generation with only one single model. More specifically, two encoders, respectively for route and language encoding, are built and shared by two decoders, respectively, for action prediction and instruction generation, so as to exploit cross-task knowledge and capture task-specific characteristics. Throughout pretraining and fine-tuning, both instruction following and generation are set as optimization objectives. We empirically verify that, compared with recent advanced task-specific solutions, LANA attains better performances on both instruction following and route description, with nearly half complexity. In addition, endowed with language generation capability, LANA can explain to humans its behaviors and assist human's wayfinding. This work is expected to foster future efforts towards building more trustworthy and socially-intelligent navigation robots.
ReLER@ZJU Submission to the Ego4D Moment Queries Challenge 2022
Nov 17, 2022



In this report, we present the ReLER@ZJU1 submission to the Ego4D Moment Queries Challenge in ECCV 2022. In this task, the goal is to retrieve and localize all instances of possible activities in egocentric videos. Ego4D dataset is challenging for the temporal action localization task as the temporal duration of the videos is quite long and each video contains multiple action instances with fine-grained action classes. To address these problems, we utilize a multi-scale transformer to classify different action categories and predict the boundary of each instance. Moreover, in order to better capture the long-term temporal dependencies in the long videos, we propose a segment-level recurrence mechanism. Compared with directly feeding all video features to the transformer encoder, the proposed segment-level recurrence mechanism alleviates the optimization difficulties and achieves better performance. The final submission achieved Recall@1,tIoU=0.5 score of 37.24, average mAP score of 17.67 and took 3-rd place on the leaderboard.