 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLana: A Language-Capable Navigator for Instruction Following and Generation
Paper and Code

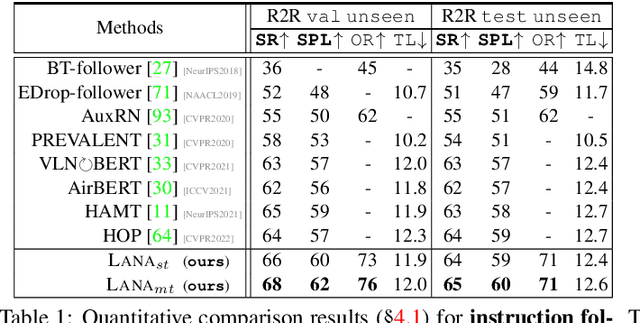


Recently, visual-language navigation (VLN) -- entailing robot agents to follow navigation instructions -- has shown great advance. However, existing literature put most emphasis on interpreting instructions into actions, only delivering "dumb" wayfinding agents. In this article, we devise LANA, a language-capable navigation agent which is able to not only execute human-written navigation commands, but also provide route descriptions to humans. This is achieved by simultaneously learning instruction following and generation with only one single model. More specifically, two encoders, respectively for route and language encoding, are built and shared by two decoders, respectively, for action prediction and instruction generation, so as to exploit cross-task knowledge and capture task-specific characteristics. Throughout pretraining and fine-tuning, both instruction following and generation are set as optimization objectives. We empirically verify that, compared with recent advanced task-specific solutions, LANA attains better performances on both instruction following and route description, with nearly half complexity. In addition, endowed with language generation capability, LANA can explain to humans its behaviors and assist human's wayfinding. This work is expected to foster future efforts towards building more trustworthy and socially-intelligent navigation robots.