 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Multispeaker Text-to-Speech under Limited-Data Scenario
Paper and Code
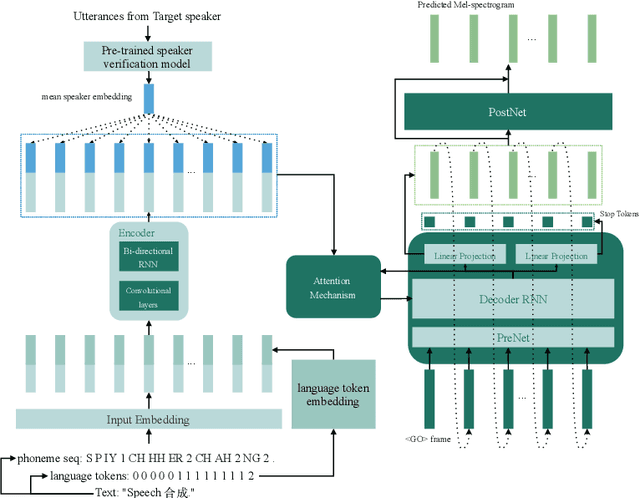


Modeling voices for multiple speakers and multiple languages in one text-to-speech system has been a challenge for a long time. This paper presents an extension on Tacotron2 to achieve bilingual multispeaker speech synthesis when there are limited data for each language. We achieve cross-lingual synthesis, including code-switching cases, between English and Mandarin for monolingual speakers. The two languages share the same phonemic representations for input, while the language attribute and the speaker identity are independently controlled by language tokens and speaker embeddings, respectively. In addition, we investigate the model's performance on the cross-lingual synthesis, with and without a bilingual dataset during training. With the bilingual dataset, not only can the model generate high-fidelity speech for all speakers concerning the language they speak, but also can generate accented, yet fluent and intelligible speech for monolingual speakers regarding non-native language. For example, the Mandarin speaker can speak English fluently. Furthermore, the model trained with bilingual dataset is robust for code-switching text-to-speech, as shown in our results and provided samples.{https://caizexin.github.io/mlms-syn-samples/index.html}.