 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgEval: A Benchmark for Zero-Shot and Few-Shot Plant Stress Phenotyping with Multimodal LLMs
Jul 29, 2024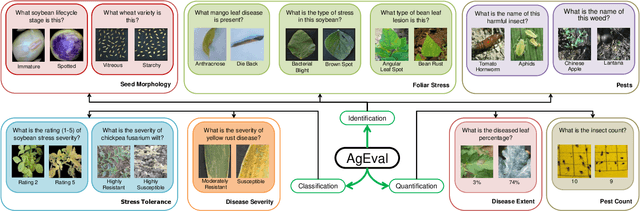
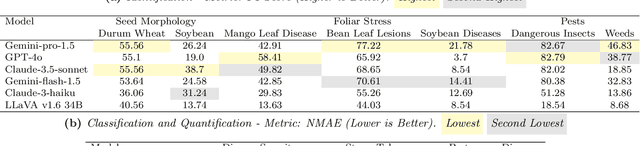
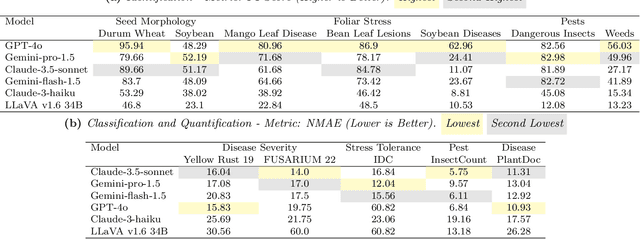
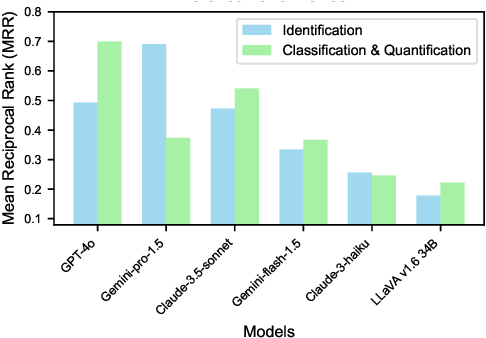
Plant stress phenotyping traditionally relies on expert assessments and specialized models, limiting scalability in agriculture. Recent advances in multimodal large language models (LLMs) offer potential solutions to this challenge. We present AgEval, a benchmark comprising 12 diverse plant stress phenotyping tasks, to evaluate these models' capabilities. Our study assesses zero-shot and few-shot in-context learning performance of state-of-the-art models, including Claude, GPT, Gemini, and LLaVA. Results show significant performance improvements with few-shot learning, with F1 scores increasing from 46.24% to 73.37% in 8-shot identification for the best-performing model. Few-shot examples from other classes in the dataset have negligible or negative impacts, although having the exact category example helps to increase performance by 15.38%. We also quantify the consistency of model performance across different classes within each task, finding that the coefficient of variance (CV) ranges from 26.02% to 58.03% across models, implying that subject matter expertise is needed - of 'difficult' classes - to achieve reliability in performance. AgEval establishes baseline metrics for multimodal LLMs in agricultural applications, offering insights into their promise for enhancing plant stress phenotyping at scale. Benchmark and code can be accessed at: https://anonymous.4open.science/r/AgEval/