 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Dependency, Data Flow, and Competitive Advantage
Mar 17, 2022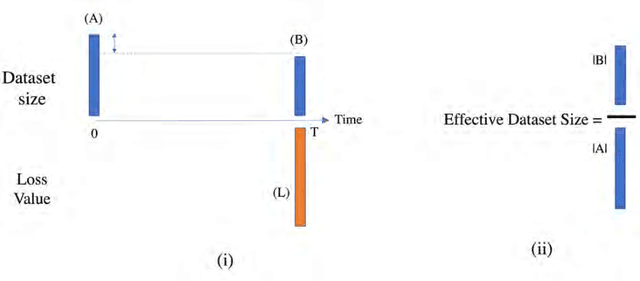

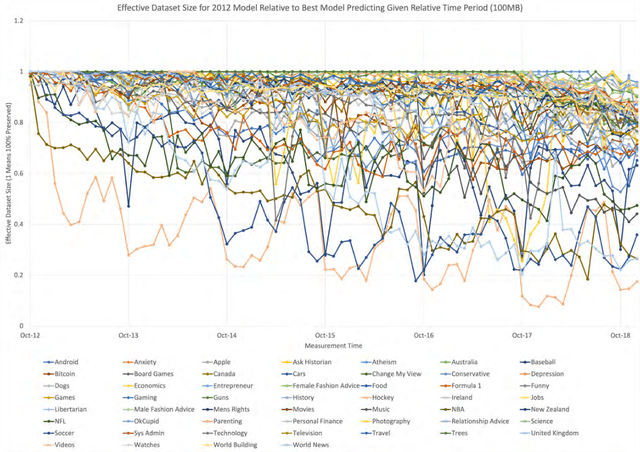
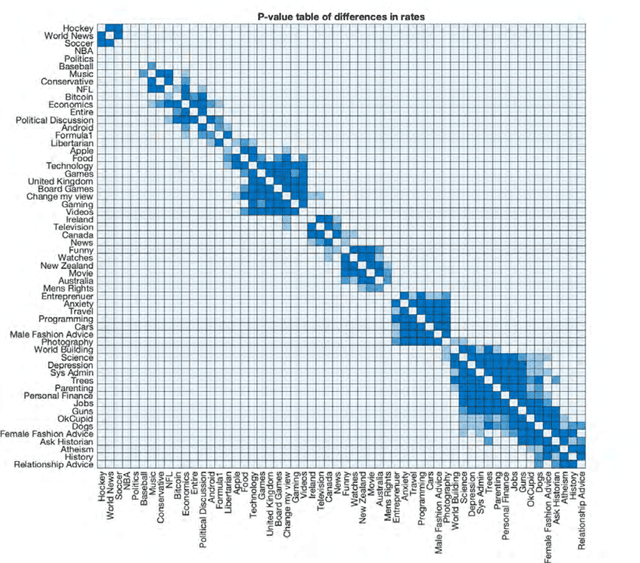
Data is fundamental to machine learning-based products and services and is considered strategic due to its externalities for businesses, governments, non-profits, and more generally for society. It is renowned that the value of organizations (businesses, government agencies and programs, and even industries) scales with the volume of available data. What is often less appreciated is that the data value in making useful organizational predictions will range widely and is prominently a function of data characteristics and underlying algorithms. In this research, our goal is to study how the value of data changes over time and how this change varies across contexts and business areas (e.g. next word prediction in the context of history, sports, politics). We focus on data from Reddit.com and compare the value's time-dependency across various Reddit topics (Subreddits). We make this comparison by measuring the rate at which user-generated text data loses its relevance to the algorithmic prediction of conversations. We show that different subreddits have different rates of relevance decline over time. Relating the text topics to various business areas of interest, we argue that competing in a business area in which data value decays rapidly alters strategies to acquire competitive advantage. When data value decays rapidly, access to a continuous flow of data will be more valuable than access to a fixed stock of data. In this kind of setting, improving user engagement and increasing user-base help creating and maintaining a competitive advantage.
Time and the Value of Data
Mar 17, 2022Managers often believe that collecting more data will continually improve the accuracy of their machine learning models. However, we argue in this paper that when data lose relevance over time, it may be optimal to collect a limited amount of recent data instead of keeping around an infinite supply of older (less relevant) data. In addition, we argue that increasing the stock of data by including older datasets may, in fact, damage the model's accuracy. Expectedly, the model's accuracy improves by increasing the flow of data (defined as data collection rate); however, it requires other tradeoffs in terms of refreshing or retraining machine learning models more frequently. Using these results, we investigate how the business value created by machine learning models scales with data and when the stock of data establishes a sustainable competitive advantage. We argue that data's time-dependency weakens the barrier to entry that the stock of data creates. As a result, a competing firm equipped with a limited (yet sufficient) amount of recent data can develop more accurate models. This result, coupled with the fact that older datasets may deteriorate models' accuracy, suggests that created business value doesn't scale with the stock of available data unless the firm offloads less relevant data from its data repository. Consequently, a firm's growth policy should incorporate a balance between the stock of historical data and the flow of new data. We complement our theoretical results with an experiment. In the experiment, we empirically measure the loss in the accuracy of a next word prediction model trained on datasets from various time periods. Our empirical measurements confirm the economic significance of the value decline over time. For example, 100MB of text data, after seven years, becomes as valuable as 50MB of current data for the next word prediction task.