 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Recommender Model Training by Dynamically Skipping Stale Embeddings
Mar 22, 2024Training recommendation models pose significant challenges regarding resource utilization and performance. Prior research has proposed an approach that categorizes embeddings into popular and non-popular classes to reduce the training time for recommendation models. We observe that, even among the popular embeddings, certain embeddings undergo rapid training and exhibit minimal subsequent variation, resulting in saturation. Consequently, updates to these embeddings lack any contribution to model quality. This paper presents Slipstream, a software framework that identifies stale embeddings on the fly and skips their updates to enhance performance. This capability enables Slipstream to achieve substantial speedup, optimize CPU-GPU bandwidth usage, and eliminate unnecessary memory access. SlipStream showcases training time reductions of 2x, 2.4x, 1.2x, and 1.175x across real-world datasets and configurations, compared to Baseline XDL, Intel-optimized DRLM, FAE, and Hotline, respectively.
Ad-Rec: Advanced Feature Interactions to Address Covariate-Shifts in Recommendation Networks
Aug 28, 2023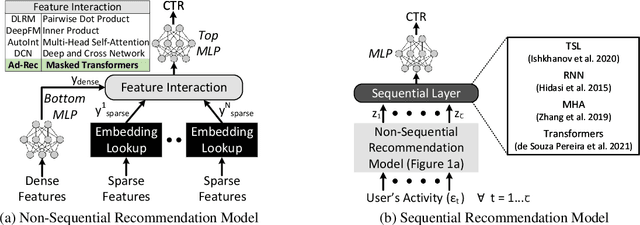
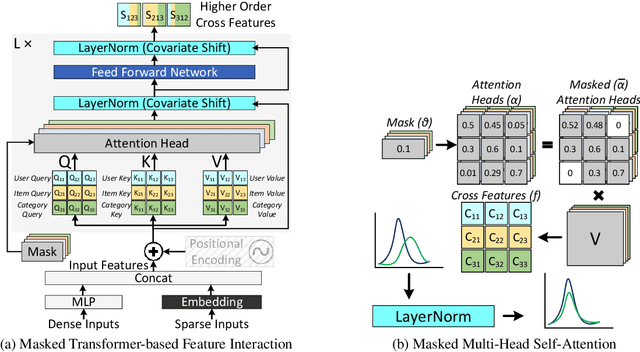

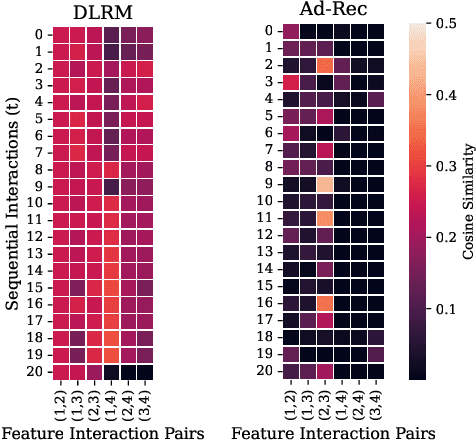
Recommendation models are vital in delivering personalized user experiences by leveraging the correlation between multiple input features. However, deep learning-based recommendation models often face challenges due to evolving user behaviour and item features, leading to covariate shifts. Effective cross-feature learning is crucial to handle data distribution drift and adapting to changing user behaviour. Traditional feature interaction techniques have limitations in achieving optimal performance in this context. This work introduces Ad-Rec, an advanced network that leverages feature interaction techniques to address covariate shifts. This helps eliminate irrelevant interactions in recommendation tasks. Ad-Rec leverages masked transformers to enable the learning of higher-order cross-features while mitigating the impact of data distribution drift. Our approach improves model quality, accelerates convergence, and reduces training time, as measured by the Area Under Curve (AUC) metric. We demonstrate the scalability of Ad-Rec and its ability to achieve superior model quality through comprehensive ablation studies.
Heterogeneous Acceleration Pipeline for Recommendation System Training
Apr 11, 2022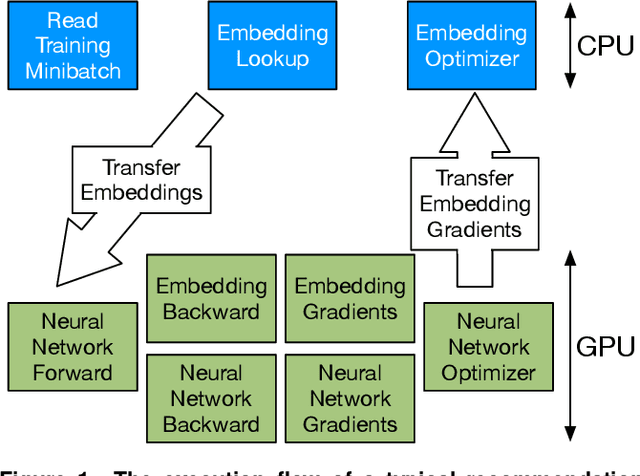

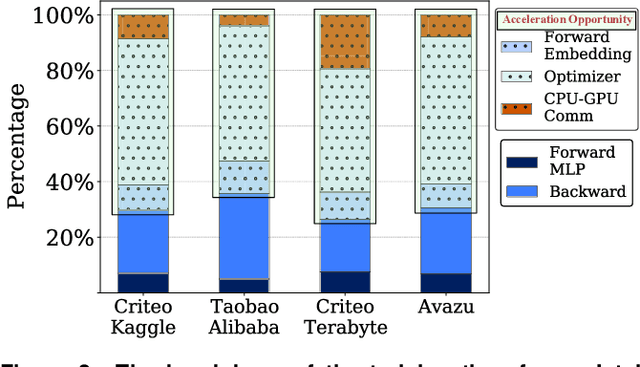

Recommendation systems are unique as they show a conflation of compute and memory intensity due to their deep learning and massive embedding tables. Training these models typically involve a hybrid CPU-GPU mode, where GPUs accelerate the deep learning portion and the CPUs store and process the memory-intensive embedding tables. The hybrid mode incurs a substantial CPU-to-GPU transfer time and relies on main memory bandwidth to feed embeddings to GPU for deep learning acceleration. Alternatively, we can store the entire embeddings across GPUs to avoid the transfer time and utilize the GPU's High Bandwidth Memory (HBM). This approach requires GPU-to-GPU backend communication and scales the number of GPUs with the size of the embedding tables. To overcome these concerns, this paper offers a heterogeneous acceleration pipeline, called Hotline. Hotline leverages the insight that only a small number of embedding entries are accessed frequently, and can easily fit in a single GPU's HBM. Hotline implements a data-aware and model-aware scheduling pipeline that utilizes the (1) CPU main memory for not-frequently-accessed embeddings and (2) GPUs' local memory for frequently-accessed embeddings. Hotline improves the training throughput by dynamically stitching the execution of popular and not-popular inputs through a novel hardware accelerator and feeding to the GPUs. Results on real-world datasets and recommender models show that Hotline reduces the average training time by 3x and 1.8x in comparison to Intel-optimized CPU-GPU DLRM and HugeCTR-optimized GPU-only baseline, respectively. Hotline increases the overall training throughput to 35.7 epochs/hour in comparison to 5.3 epochs/hour for the Intel-optimized DLRM baseline
High-Performance Training by Exploiting Hot-Embeddings in Recommendation Systems
Mar 02, 2021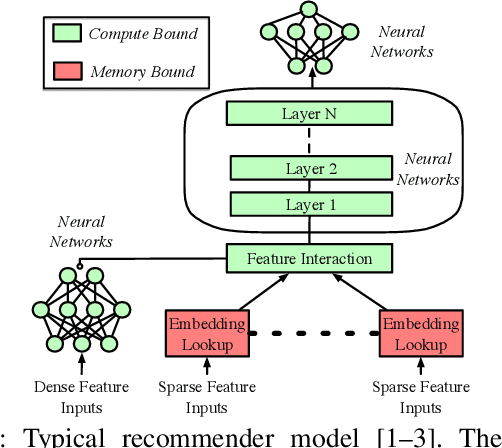
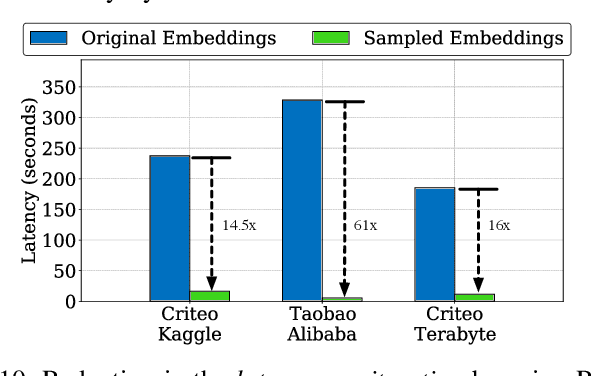
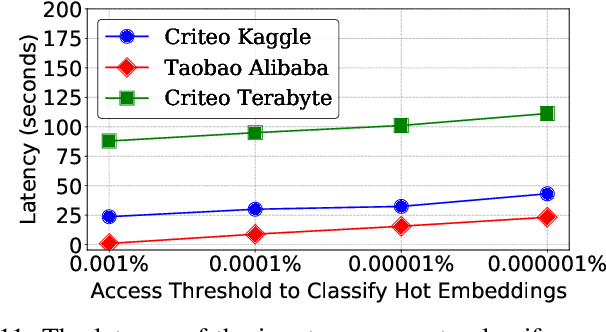
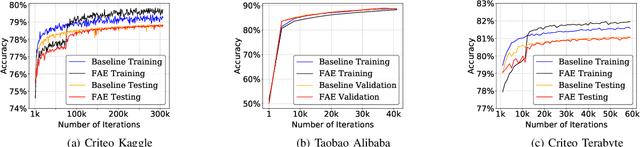
Recommendation models are commonly used learning models that suggest relevant items to a user for e-commerce and online advertisement-based applications. Current recommendation models include deep-learning-based (DLRM) and time-based sequence (TBSM) models. These models use massive embedding tables to store a numerical representation of item's and user's categorical variables (memory-bound) while also using neural networks to generate outputs (compute-bound). Due to these conflicting compute and memory requirements, the training process for recommendation models is divided across CPU and GPU for embedding and neural network executions, respectively. Such a training process naively assigns the same level of importance to each embedding entry. This paper observes that some training inputs and their accesses into the embedding tables are heavily skewed with certain entries being accessed up to 10000x more. This paper tries to leverage skewed embedded table accesses to efficiently use the GPU resources during training. To this end, this paper proposes a Frequently Accessed Embeddings (FAE) framework that exposes a dynamic knob to the software based on the GPU memory capacity and the input popularity index. This framework efficiently estimates and varies the size of the hot portions of the embedding tables within GPUs and reallocates the rest of the embeddings on the CPU. Overall, our framework speeds-up the training of the recommendation models on Kaggle, Terabyte, and Alibaba datasets by 2.34x as compared to a baseline that uses Intel-Xeon CPUs and Nvidia Tesla-V100 GPUs, while maintaining accuracy.