 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Performance Training by Exploiting Hot-Embeddings in Recommendation Systems
Paper and Code
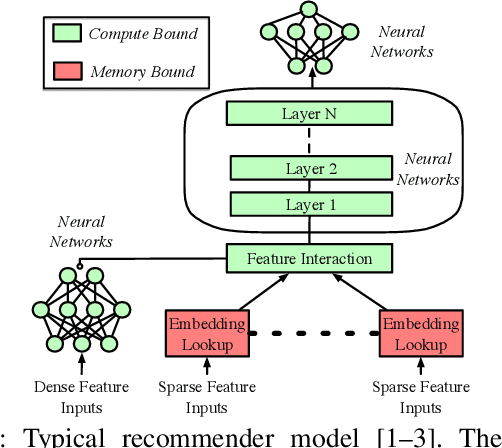
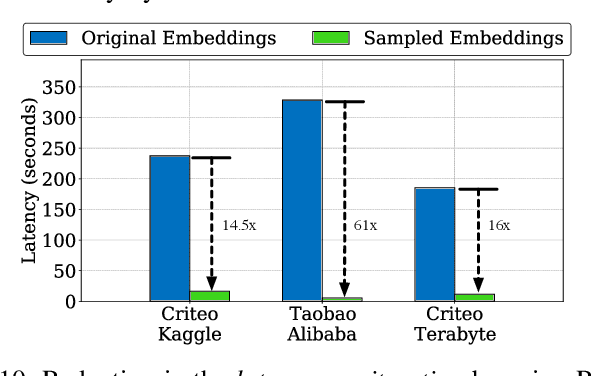
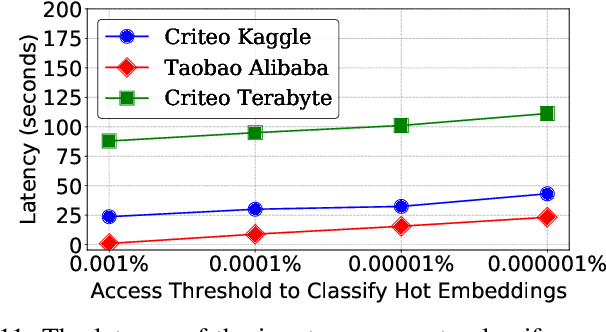
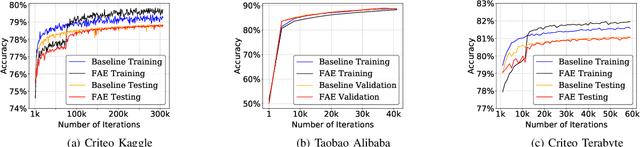
Recommendation models are commonly used learning models that suggest relevant items to a user for e-commerce and online advertisement-based applications. Current recommendation models include deep-learning-based (DLRM) and time-based sequence (TBSM) models. These models use massive embedding tables to store a numerical representation of item's and user's categorical variables (memory-bound) while also using neural networks to generate outputs (compute-bound). Due to these conflicting compute and memory requirements, the training process for recommendation models is divided across CPU and GPU for embedding and neural network executions, respectively. Such a training process naively assigns the same level of importance to each embedding entry. This paper observes that some training inputs and their accesses into the embedding tables are heavily skewed with certain entries being accessed up to 10000x more. This paper tries to leverage skewed embedded table accesses to efficiently use the GPU resources during training. To this end, this paper proposes a Frequently Accessed Embeddings (FAE) framework that exposes a dynamic knob to the software based on the GPU memory capacity and the input popularity index. This framework efficiently estimates and varies the size of the hot portions of the embedding tables within GPUs and reallocates the rest of the embeddings on the CPU. Overall, our framework speeds-up the training of the recommendation models on Kaggle, Terabyte, and Alibaba datasets by 2.34x as compared to a baseline that uses Intel-Xeon CPUs and Nvidia Tesla-V100 GPUs, while maintaining accuracy.