 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Acceleration Pipeline for Recommendation System Training
Paper and Code
Apr 11, 2022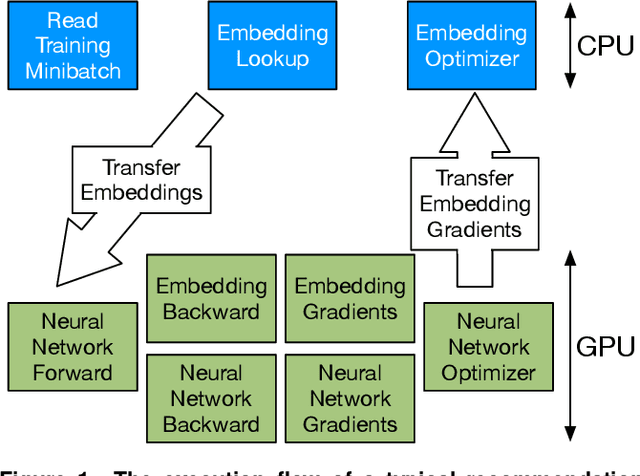

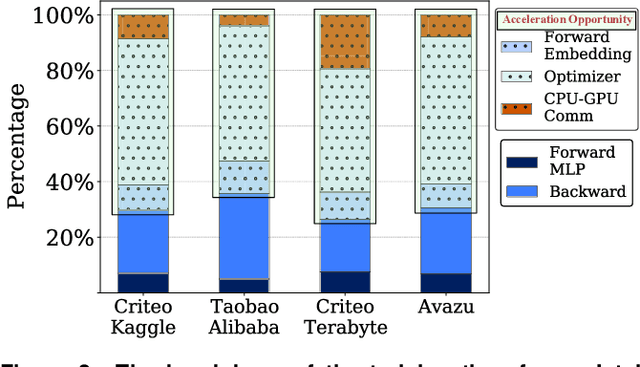

Recommendation systems are unique as they show a conflation of compute and memory intensity due to their deep learning and massive embedding tables. Training these models typically involve a hybrid CPU-GPU mode, where GPUs accelerate the deep learning portion and the CPUs store and process the memory-intensive embedding tables. The hybrid mode incurs a substantial CPU-to-GPU transfer time and relies on main memory bandwidth to feed embeddings to GPU for deep learning acceleration. Alternatively, we can store the entire embeddings across GPUs to avoid the transfer time and utilize the GPU's High Bandwidth Memory (HBM). This approach requires GPU-to-GPU backend communication and scales the number of GPUs with the size of the embedding tables. To overcome these concerns, this paper offers a heterogeneous acceleration pipeline, called Hotline. Hotline leverages the insight that only a small number of embedding entries are accessed frequently, and can easily fit in a single GPU's HBM. Hotline implements a data-aware and model-aware scheduling pipeline that utilizes the (1) CPU main memory for not-frequently-accessed embeddings and (2) GPUs' local memory for frequently-accessed embeddings. Hotline improves the training throughput by dynamically stitching the execution of popular and not-popular inputs through a novel hardware accelerator and feeding to the GPUs. Results on real-world datasets and recommender models show that Hotline reduces the average training time by 3x and 1.8x in comparison to Intel-optimized CPU-GPU DLRM and HugeCTR-optimized GPU-only baseline, respectively. Hotline increases the overall training throughput to 35.7 epochs/hour in comparison to 5.3 epochs/hour for the Intel-optimized DLRM baseline