 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocratic Questioning: Learn to Self-guide Multimodal Reasoning in the Wild
Jan 07, 2025
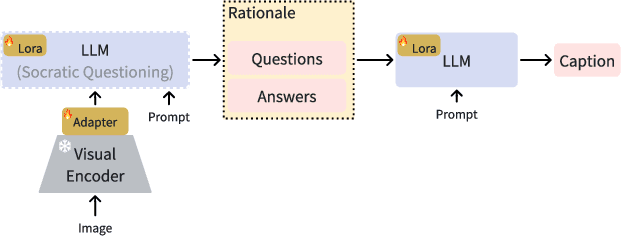

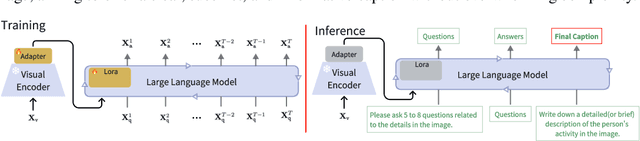
Complex visual reasoning remains a key challenge today. Typically, the challenge is tackled using methodologies such as Chain of Thought (COT) and visual instruction tuning. However, how to organically combine these two methodologies for greater success remains unexplored. Also, issues like hallucinations and high training cost still need to be addressed. In this work, we devise an innovative multi-round training and reasoning framework suitable for lightweight Multimodal Large Language Models (MLLMs). Our self-questioning approach heuristically guides MLLMs to focus on visual clues relevant to the target problem, reducing hallucinations and enhancing the model's ability to describe fine-grained image details. This ultimately enables the model to perform well in complex visual reasoning and question-answering tasks. We have named this framework Socratic Questioning(SQ). To facilitate future research, we create a multimodal mini-dataset named CapQA, which includes 1k images of fine-grained activities, for visual instruction tuning and evaluation, our proposed SQ method leads to a 31.2% improvement in the hallucination score. Our extensive experiments on various benchmarks demonstrate SQ's remarkable capabilities in heuristic self-questioning, zero-shot visual reasoning and hallucination mitigation. Our model and code will be publicly available.
A Theoretical View of Linear Backpropagation and Its Convergence
Dec 21, 2021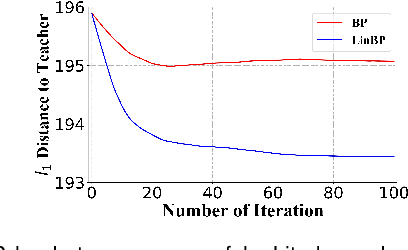
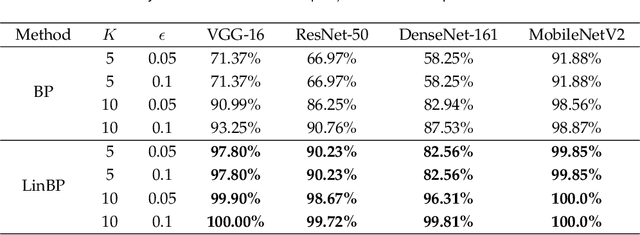
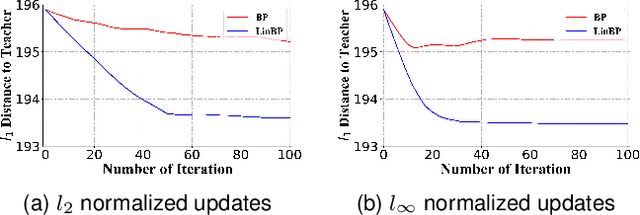
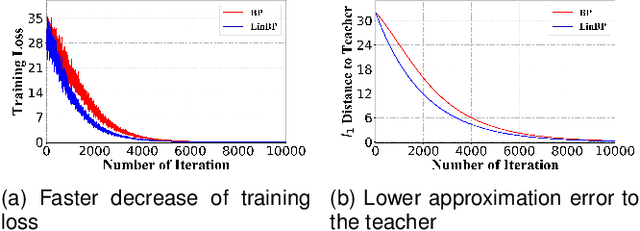
Backpropagation is widely used for calculating gradients in deep neural networks (DNNs). Applied often along with stochastic gradient descent (SGD) or its variants, backpropagation is considered as a de-facto choice in a variety of machine learning tasks including DNN training and adversarial attack/defense. Recently, a linear variant of BP named LinBP was introduced for generating more transferable adversarial examples for black-box adversarial attacks, by Guo et al. Yet, it has not been theoretically studied and the convergence analysis of such a method is lacking. This paper serves as a complement and somewhat an extension to Guo et al.'s paper, by providing theoretical analyses on LinBP in neural-network-involved learning tasks including adversarial attack and model training. We demonstrate that, somewhat surprisingly, LinBP can lead to faster convergence in these tasks in the same hyper-parameter settings, compared to BP. We confirm our theoretical results with extensive experiments.