 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocratic Questioning: Learn to Self-guide Multimodal Reasoning in the Wild
Jan 07, 2025
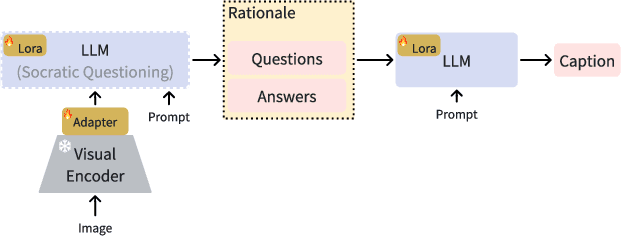

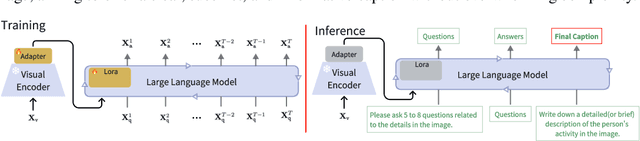
Complex visual reasoning remains a key challenge today. Typically, the challenge is tackled using methodologies such as Chain of Thought (COT) and visual instruction tuning. However, how to organically combine these two methodologies for greater success remains unexplored. Also, issues like hallucinations and high training cost still need to be addressed. In this work, we devise an innovative multi-round training and reasoning framework suitable for lightweight Multimodal Large Language Models (MLLMs). Our self-questioning approach heuristically guides MLLMs to focus on visual clues relevant to the target problem, reducing hallucinations and enhancing the model's ability to describe fine-grained image details. This ultimately enables the model to perform well in complex visual reasoning and question-answering tasks. We have named this framework Socratic Questioning(SQ). To facilitate future research, we create a multimodal mini-dataset named CapQA, which includes 1k images of fine-grained activities, for visual instruction tuning and evaluation, our proposed SQ method leads to a 31.2% improvement in the hallucination score. Our extensive experiments on various benchmarks demonstrate SQ's remarkable capabilities in heuristic self-questioning, zero-shot visual reasoning and hallucination mitigation. Our model and code will be publicly available.
From Text to Mask: Localizing Entities Using the Attention of Text-to-Image Diffusion Models
Sep 08, 2023Diffusion models have revolted the field of text-to-image generation recently. The unique way of fusing text and image information contributes to their remarkable capability of generating highly text-related images. From another perspective, these generative models imply clues about the precise correlation between words and pixels. In this work, a simple but effective method is proposed to utilize the attention mechanism in the denoising network of text-to-image diffusion models. Without re-training nor inference-time optimization, the semantic grounding of phrases can be attained directly. We evaluate our method on Pascal VOC 2012 and Microsoft COCO 2014 under weakly-supervised semantic segmentation setting and our method achieves superior performance to prior methods. In addition, the acquired word-pixel correlation is found to be generalizable for the learned text embedding of customized generation methods, requiring only a few modifications. To validate our discovery, we introduce a new practical task called "personalized referring image segmentation" with a new dataset. Experiments in various situations demonstrate the advantages of our method compared to strong baselines on this task. In summary, our work reveals a novel way to extract the rich multi-modal knowledge hidden in diffusion models for segmentation.