 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXMODD: An EXplanatory Multimodal Open-Domain Dialogue dataset
Oct 17, 2023


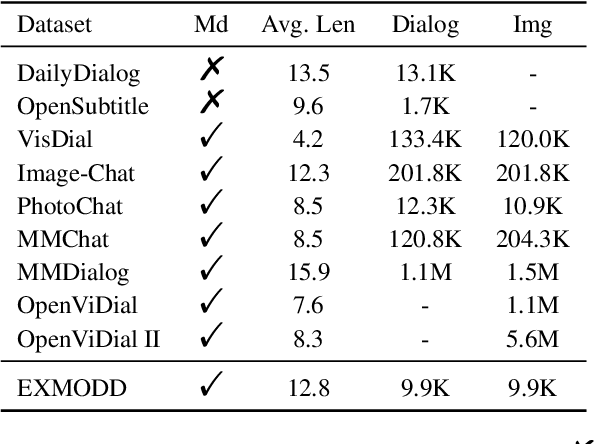
The need for high-quality data has been a key issue hindering the research of dialogue tasks. Recent studies try to build datasets through manual, web crawling, and large pre-trained models. However, man-made data is expensive and data collected from the internet often includes generic responses, meaningless statements, and toxic dialogues. Automatic data generation through large models is a cost-effective method, but for open-domain multimodal dialogue tasks, there are still three drawbacks: 1) There is currently no open-source large model that can accept multimodal input; 2) The content generated by the model lacks interpretability; 3) The generated data is usually difficult to quality control and require extensive resource to collect. To alleviate the significant human and resource expenditure in data collection, we propose a Multimodal Data Construction Framework (MDCF). MDCF designs proper prompts to spur the large-scale pre-trained language model to generate well-formed and satisfactory content. Additionally, MDCF also automatically provides explanation for a given image and its corresponding dialogue, which can provide a certain degree of interpretability and facilitate manual follow-up quality inspection. Based on this, we release an Explanatory Multimodal Open-Domain dialogue dataset (EXMODD). Experiments indicate a positive correlation between the model's ability to generate accurate understandings and high-quality responses. Our code and data can be found at https://github.com/poplpr/EXMODD.